München, Starnberg, 06. Sept. 2021 - Deep-Learning-Systeme sind bei Datenerfassung- und Verarbeitung eine echte Herausforderung für die Speicher- und GPU-Infrastruktur…
Zum Hintergrund: Erfolgreiche Autonome Fahrzeug - Entwicklung hängt zu großen Teilen davon ab, die Modelle so zu trainieren, dass sie unter allen Straßen- und Wetterbedingungen und unter Einhaltung der verschiedenen Gesetze & Vorschriften performant, sicher und zuverlässig funktionieren. Deep-Learning-Systeme stellen dabei durch die Geschwindigkeit der Datenerfassung und -verarbeitung eine starke Belastung für die Speicher- und Berechnungsinfrastruktur dar. Ein einzelnes Fahrzeug erzeugt und verbraucht TB's im mittleren zweistelligen Bereich, was die sich bei einer Flotte von Trainingsfahrzeugen vervielfacht. Die tägliche Datenerfassung beläuft sich typischerweise dann auf mehrere Petabytes, die in das Data Lake eingespeist werden müssen.
Weitere Herausforderung: Volle Auslastung der teuren GPU-Server
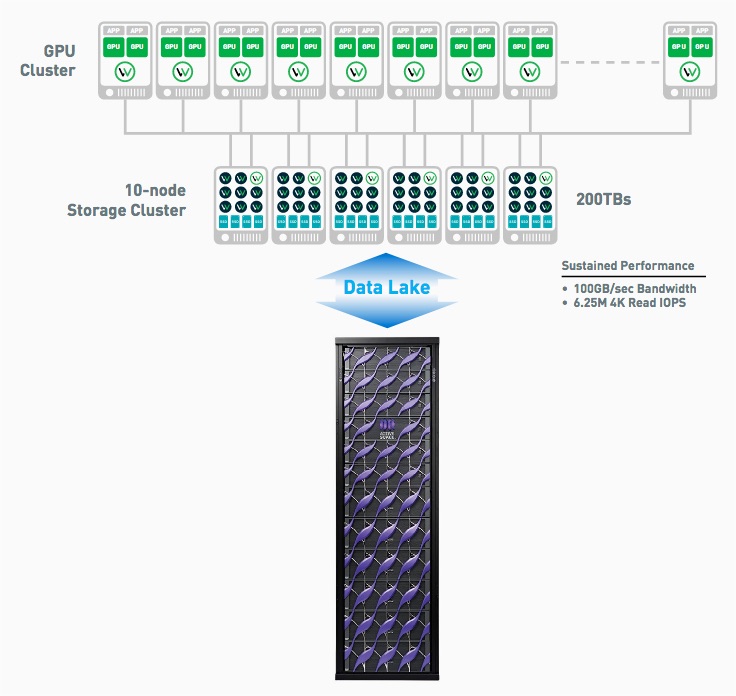
Nach vorliegenden Angaben von Quantum (1) entwickelt ein führender AV-Hersteller seine Trainingsmodelle auf einem kleinen Cluster aus zehn GPU-Server und einem gemeinsam genutzten Datenspeicher, der auf einer kommerziellen All-Flash-NAS-Appliance aufgebaut ist. Diese Lösung funktionierte danach gut für die anfängliche Modellentwicklung, aber es wurde klar, dass sie nicht auf ein volles Produktionssystem mit 50 bis 100 GPU-Servern skaliert werden konnte, das täglich Petabytes an neuen Daten verarbeiten musste. Die Datensätze, die zum Trainieren der KI-Modelle verwendet wurden, bestanden aus Millionen von 4K-Bilddateien, die mit einigen mittelgroßen 100 MB-Dateien und einigen sehr großen Dateien mit mehreren Gigabyte Größe vermischt waren, die alle mit sehr hoher Bandbreite (bis zu 10 GByte/Sekunde) gelesen werden mussten, um die GPU-Server voll auszulasten.
Das ursprüngliche All-Flash-NAS-System konnte 1-1,5 GByte/Sekunde erreichen, so dass die GPU-Server nicht ausreichend mit Daten versorgt wurden. Die Entwickler hatten mit den Einschränkungen von NFS zu kämpfen und dazu eine Methode entwickelt, um Trainingsdatensätze auf die lokalen NVMe-Laufwerke des GPU-Servers zu kopieren, um die Trainingszeiten insgesamt zu verbessern, aber diese Lösung ließ sich nicht auf Cluster in Produktionsgröße übertragen.
Weiter mussten die Trainingssysteme das Dateisystem routinemäßig durchlaufen, um neue Dateien für die Trainingsläufe auszuwählen. Ein einziger Dateisystemdurchlauf dauerte Stunden, während die GPUs im Leerlauf blieben. Eine Unterauslastung der GPUs von nur 10 % würde danach bei einem Produktionscluster mit 50 GPU-Servern zu einer Verschwendung von über 2 Mio. US Dollar an GPU-Server-Infrastruktur führen.
Die Produktionslösung musste eine Ingest-Rate mit hoher Bandbreite und geringer Latenz aufweisen, die eine 100-Gbit-Netzwerkverbindung mit 10 GByte/Sekunde pro GPU-Server sättigen konnte, um die Ingest-Anforderungen zu erfüllen.
Kostenüberschreitung
Frühe Entwicklungssysteme in dem Anwendungsbeispiel hatten für den Schulungskatalog All-Flash-Appliances von traditionellen Speicheranbietern verwendet. Das Team erkannte jedoch, dass es sich nicht leisten konnte, mit dieser Architektur auf Produktionsniveau zu skalieren, da die Speicherung von Petabytes an Daten auf Flash-Speicher zu kostspielig war.
Flash wurde nur benötigt, um die Leistung für die GPU-Cluster bereitzustellen, war aber für den Datenkatalog nicht sinnvoll. Die Lösung musste eine festplattenbasierte Architektur mit ihrer niedrigeren Kostenstruktur integrieren und softwaredefiniert sein, um flexible Beschaffungsoptionen für die zugrunde liegende Hardwareinfrastruktur zu ermöglichen.
(1) Quelle: Quantum Corp. "Improving GPU Utilization for Autonomous Vehicle", Solutions Brief
Link > https://www.quantum.com/en/products/object-storage/
Zur Lösung: Kombination aus WekaIO Matrix Software und Quantum ActiveScale Cloud Object Storage System
Matrix ist ein paralleles verteiltes Dateisystem, das sowohl Daten als auch Metadaten über die hochskalierbare Speicherinfrastruktur von ActiveScale verteilt, um einen massiv parallelen Datenzugriff zu gewährleisten. Matrix liefert niedrige Latenzzeiten bei hoher Bandbreitenleistung für Daten- und Metadatenoperationen, während ActiveScale extreme Datenbeständigkeit und -integrität im Petabyte-Maßstab bereitstellen kann, um die Daten geschützt und hochverfügbar zu halten.
Die Kombination aus Quantum ActiveScale Cloud-Objektspeichersystem und WekaIOs Matrix-Dateisystem ermöglichte es einem Hersteller von autonomen Fahrzeugen, die Leistung seines GPU-Clusters um das 7-fache im Vergleich zu älteren NFS-basierten All-Flash NAS-Lösungen zu verbessern. Weiter konnte die Leistung um das 2-fache im Vergleich zu lokal angeschlossenen NVMe-Laufwerken erhöht werden und die Metadatenleistung stieg um den Faktor 3, was zu einer verbesserten GPU-Auslastung führte.
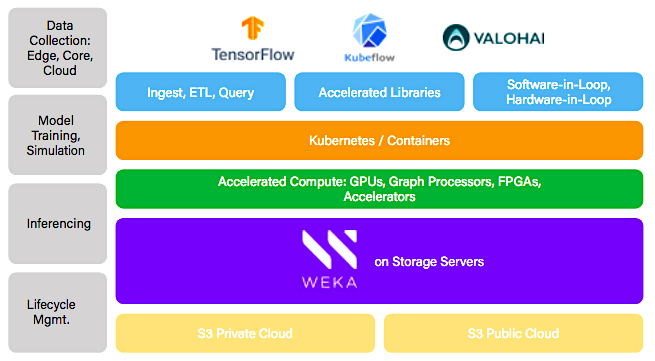
Abb.: "Weka AI solutions framework enables Accelerated DataOps from the Edge to Core to Cloud" (Bildquelle: WekaIO)
Querverweis:
Unser Beitrag > Quantum Mobile Storage unterstützt bei der Entwicklung autonomer Fahrzeuge
Unser Blogpost > Gestiegene Speicheranforderungen im Zuge der Entwicklung von KI-Anwendungen
Link > Disruptive trends that will transform the auto industry, by Paul Gao, Hans-Werner Kaas, Detlev Mohr, and Dominik Wee. McKinsey&Company, Automotive & Assembly.