Berlin, Starnberg, 05. Nov. 2018 - Trend geht in Richtung Echtzeit-Verarbeitung; Stellungnahme von Data Artisans (Apache Flink) zu derzeitigen Entwicklungen...
Zum Hintergrund: Cloudera und Hortonworks gaben kürzlich bekannt, fusionieren zu wollen und beide Unternehmen bieten Hadoop-Frameworks an. Apache Hadoop ermöglicht intensive Rechenprozesse mit Big Data auf Compute-Clustern und ist seit 2008 ein Top Level-Projekt der Apache Software Foundation. Der Zusammenschluss wird von Experten zur Zeit unterschiedlich bewertet. Wie manche das Zusammenführen von Knowhow und Ressourcen als Stärkung betrachten, sehen andere in dem Merger eher ein Zeichen für die zunehmende Schwächung von Hadoop. Unabhängig davon zeigen die jüngsten Entwicklungen jedenfalls, wie groß die Dynamik im Umfeld der Big Data-Verarbeitung ist. Dazu tragen nicht zuletzt Entwicklungen wie die rapide Zunahme unstrukturierter Daten, ein Boom im Bereich Machine Learning und die rapide voranschreitende Digitalisierung generell in den Unternehmen bei.
Für data Artisans, ein junges deutsches Software-Unternehmen, dessen Gründer maßgeblich an der Entwicklung an Apache Flink beteiligt waren (und noch immer sind), geht der Trend klar in Richtung Data Streaming, d.h. der Verarbeitung von Big Data in nahezu Echtzeit. Nachfolgend finden Sie eine Stellungnahme des Unternehmens zu den aktuellen und kommenden Entwicklungen rund um die Verarbeitung von Big Data.
Auf dem jüngsten Gartner Symposium/ITxpo 2018 stellte Gartner die Ergebnisse seiner jährlichen globalen CIO-Umfrage vor. Diese zeigt, dass das digitale Geschäft in diesem Jahr einen „Wendepunkt“ erreicht hat, wobei fast die Hälfte der CIOs angibt, dass ihr Unternehmen „bereits die Geschäftsmodelle verändert hat“. Eines der Merkmale des digitalen Geschäfts ist, dass es ereignisgesteuert ist und einen Übergang zu ereigniszentrierten Technologien und einer ebenso ereigniszentrierten Datenstrategie erfordert.
Das ist auch keine Überraschung, denn die meisten Geschäftsdaten werden als kontinuierlicher Ereignisstrom erzeugt: Sensormessungen, Website-Klicks, Interaktionen mit mobilen Anwendungen, Datenbank-Änderungen, Anwendungs- und Maschinenprotokolle, Aktienhandel und Finanztransaktionen... Bei der Betrachtung der boomenden Technologiebereiche – wie künstliche Intelligenz, maschinelles Lernen, Echtzeit-Analytik und IoT – wird eines deutlich: Leistungsstarke Systeme, die Ereignisse in Echtzeit verarbeiten und Unternehmen in die Lage versetzen, auf neue Chancen, Kundenanfragen und dynamische Marktbedingungen zu reagieren, sind unerlässlich, um wettbewerbsfähig zu bleiben.
Mit der Umstellung auf digitale Geschäftsmodelle findet eine entsprechende Verschiebung in der Akzeptanz der zugrundeliegenden Big-Data-Technologien statt. Der diesjährige Big Data Trends and Challenges Survey Report von Qubole zeigt, dass MapReduce, die native Batch-Verarbeitungsmaschine von Hadoop, mit dem größten Nutzungsrückgang konfrontiert ist, während Apache Flink zu dem am schnellsten wachsenden Open-Source-Datenverarbeitungs-Framework avanciert ist.
Da Stream-Processing-Plattformen wie Apache Flink entwicklerfreundlicher geworden sind, erleben wir aus verschiedenen Gründen eine schnell wachsende Akzeptanz. So können Flink-Programme jetzt viel kompakter sein und von einem containerbasierten Setup profitieren, woraus weniger Netzwerkverkehr und bessere Performance resultieren. Ein Beweis für dieses Wachstum ist die Zunahme der Kubernetes-Implementierungen im Vergleich zu den YARN-Implementierungen. Die Entwicklung dieser neuen operativen Anwendungen wird zunehmend von Produktteams geleitet, die eher Big-Data-Teams sind.
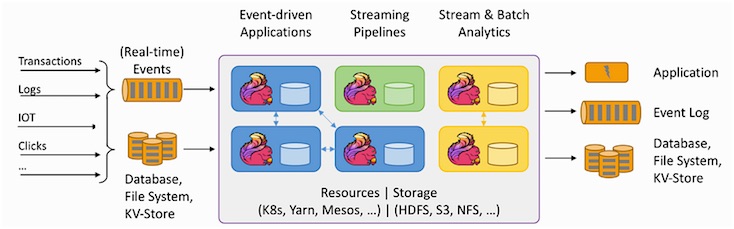
Abb. 1: Apache Flink® - Stateful Computations over Data Streams (Bildquelle: Apache Flink)
Schließlich realisieren Unternehmen mit Echtzeit-Datentechnologien messbare Geschäftsvorteile schneller als mit herkömmlicher Batch-Verarbeitung und historischer Analytik. Es hat sich gezeigt, dass die Einführung von Flink in Unternehmen mit sehr spezifischen Anwendungsfällen beginnt statt Projekten mit offenem Ende. Unternehmen realisieren den Business-ROI schneller, weil sie im ersten Schritt Live-Anwendungen in Betrieb nehmen. Zum Beispiel verzeichnete Alibaba nach einem Jahr Flink in der Produktion eine 30-prozentige Steigerung der Konversionsrate während des Singles Day 2016 (25 Milliarden US-Dollar an Waren, die an einem einzigen Tag in diesem Jahr verkauft wurden). Apache Flink ist schnell gereift. Es bietet eine einheitliche Plattform für die Stream- und Batch-Verarbeitung – und es gibt keinen wesentlichen Grund für diese Unterscheidung und die Entwicklung der Technologie. Viele Anwendungen benötigen beide Funktionen, so dass es am Ende um die Echtzeit-Datenverarbeitung geht.
Die Stream-Verarbeitung expandiert immer weiter über die schnelle Übertragung von Daten oder einfache analytische Anwendungen hinaus zu operativen und transaktionalen Anwendungen, die die zustandsabhängigen Funktionen tatsächlich nutzen. Große globale Unternehmen aus allen Branchen setzen Streaming-Data-Anwendungen zur Erkennung von Anomalien in Cloud-Aktivitäten, Smart City Traffic Monitoring, Machine Learning Model Training, Risikobewertung für Trades sowie Performance- und Fehleranalyse für serviceorientierte Architekturen ein, unter anderem mit verteilten Tracing-Techniken.
Im September präsentierte data Artisans die branchenweit ersten serialisierbaren ACID-Transaktionen (ACID = Atomicity, Consistency, Isolation, Durability) direkt auf Streaming-Daten. Streaming Ledger wurde speziell für die Anforderungen moderner digitaler Unternehmen entwickelt und bietet einen hohen Durchsatz, so dass umfangreiche Anwendungen wie Bestandsmanagement, Preisgestaltung, Abrechnung, Angebots-Nachfrage-Matching, Logistik oder Positionsführung effizient in konsistente Streaming-Anwendungen umgewandelt werden können, ohne dass eine zugrundeliegende Datenbank erforderlich ist. Diese Anwendungen können nun alle Vorteile der Datenstromverarbeitung voll ausschöpfen und sich auf natürliche Weise in eine Streaming-Data-Architektur einfügen, wodurch die Reichweite der Datenstromverarbeitung weiter erhöht wird.
Fazit von Data Artisans
"Die Umstellung auf Stream Processing ist unerlässlich und geht über die Datenarchitektur des Unternehmens hinaus, die modernisiert werden muss, um neue Echtzeitanwendungen und Anwendungsfälle zu unterstützen, die ältere Systeme nicht effektiv unterstützen. Unternehmen müssen die Stream-Verarbeitung verinnerlichen und die kulturelle Transformation von einem „datenzentrierten“ zu einem „ereigniszentrierten“ Unternehmen beginnen. Sie müssen ihre Mitarbeiter schulen und potenzielle Qualifikationslücken ihrer Teams schließen, um für die neue Ära gerüstet zu sein, in der die Stream-Verarbeitung im Mittelpunkt des Nervensystems des Unternehmens steht.“
Abb. 2: Apache Flink is an open source stream processing framework for high-performance, scalable, and accurate real-time applications (Bild-/Textquelle: Data Artisans)