Starnberg, 08. Okt. 2018 - Deep Learning, Autonomes Fahren, Robotic-basierte Prozessautomatisierung; auf den richtigen Storage und dessen Verwaltung kommt es an...
Zum Hintergrund: Nach Prognosen des McKinsey Global Institute kann Künstliche Intelligenz das globale Bruttoinlandsprodukt bis 2030 zusätzlich um durchschnittlich 1,2 Prozentpunkte pro Jahr steigern. (1) Einsatzbereiche wie die automatische Bilderkennung, natürliche Sprache, virtuelle Assistenten oder fortgeschrittenes maschinelles Lernen (siehe Predictive Maintainance) sind neben den bekannten Entwicklungen im automobilen Umfeld (autonomes Fahren) jedoch nicht nur aus ökonomischen- und Software-Entwicklungsaspekten interessant, sondern diese produzieren auch eine zunehmende Flut von Daten (block, strukturiert-/semi-unstrukturiert), die für alle Beteiligten zum Problem werden können. Womit wir wieder beim Thema Storage sind... Eine klug gewählte Daten- und Speichermanagement - Strategie unterstützt eine leistungsfähige und kosteneffiziente Umsetzung von KI-Initiativen und schafft die Grundlagen für den geschäftlichen Nutzen dieser vielversprechenden Technologien.
Storage-Anforderungen im Bereich selbstfahrender Fahrzeuge
Für die Datenerfassung zur Entwicklung sicherer selbstfahrender Fahrzeuge werden spezifische Sensoren sowie Radar, Kameras, Ultraschall usw. benutzt. Das Datenvolumen, das von einem einzelnen Versuchsfahrzeug dabei erzeugt wird, beträgt in der Regel über 1 TB pro Stunde. Um KI für die Anforderungen selbstfahrender Fahrzeuge zu trainieren, besteht eine der Herausforderungen deshalb in der Skalierung; zudem existieren weiteren vielfältige Herausforderungen: Die Menge und auch Größe der Datensätze z.B. gehen weit über die Möglichkeiten der lokalen Speicherung einer Trainingsmaschine hinaus, daher ist der Einsatz von lokalem Caching (SSD, DRAM) bei großen und sehr vielen Datensätzen begrenzt; ein leistungsfähiges Speicher-Backend ist erforderlich. GPU-Spezialist NVIDIA sieht nach eigenen Angaben deshalb auch immer mehr Implementierungen von Flash-Speicher oder Flash-beschleunigtem Hybrid-Storage in Verbindung mit (parallelen) High-Performance-Filesystemen (Quelle: NVIDIA Blog, siehe unten), was allerdings das Backend nicht einfacher in der Verwaltung macht.
Ein weiterer Punkt betrifft die Leistungsfähigkeit des Gesamtsystems. Eine automatisierte End-to-end Speicher- und Data Management Architektur legt aktiv genutzte ("hot") Daten auf sehr schnelle Speicher (Flash, SCM, DRAM) ab, während weniger genutzte Daten auf die kostengünstigere Archivebene verschoben werden (HDD, Tape, Cloud). Die Kosten für den Storage können damit deutlich gesenkt werden. Für die Entwicklung von autonomen Fahrzeugen ist dies entscheidend, da sehr große Datenmengen generiert werden, die über mehrere Jahre lang gespeichert werden müssen. Ferner werden damit gesetzliche Compliance-Richtlinien eingehalten und Algorithmen lassen sich für die weitere Entwicklungsarbeit validieren.
GPUs, CPUs und Storage
Um ein ausgewogenes Systemdesign zu erreichen, müssen den GPUs genügend Daten zur Verfügung stehen, das ist nicht anders als bei jeder konventionellen Server-Applikationsumgebung (Stichwort: Balanced System); Verzögerungen führen zu unausgelasteten GPUs und der gesamte Prozess wird verlangsamt. Die Bandbreite der Datenübermittlung ist hoch und ein einzelner Knoten kann Daten mit >3 GB/s verarbeiten, insbesondere wenn hochauflösender Bilder - also große Datensätze - entstehen. Bei kleineren Datensätzen ist das Problem nicht so groß, weil das neuronale Netzwerk innerhalb jeder Trainingseinheit auf die gleichen Daten zugreift. Diese können dann lokal auf Flash oder RAM zwischengespeichert werden.
Innerhalb von nur zwei Jahren stieg die von Deep-Learning - Algorithmen benötigte Rechenleistung um das 15fache, während die von GPUs gelieferte Rechenleistung um das 10fache anstieg. Parallel ist das Volumen an unstrukturierten Daten bei KI mit DL-Apps massiv angestiegen ist und GPUs arbeiten massiv parallel (Compute Cluster); hier sind traditionelle bzw. ältere Speichersysteme überfordert. Diese wurden in der Vergangenheit für die serielle Verarbeitung entwickelt (siehe SCSI).
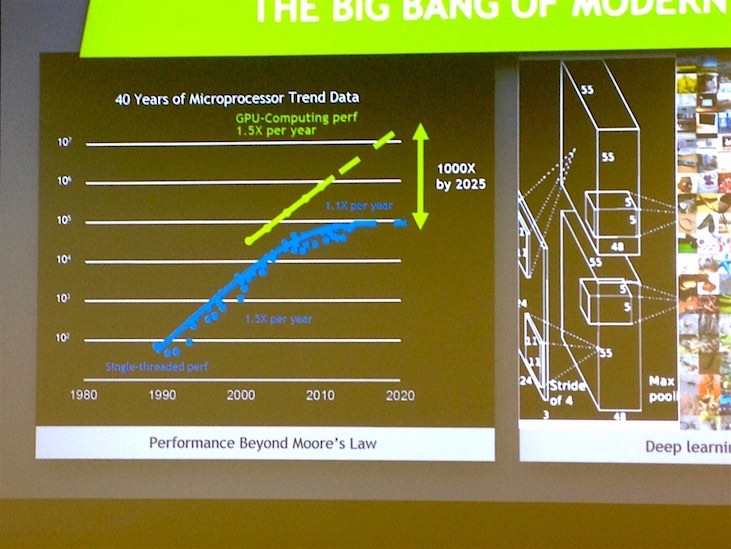
Abb. 1: Bildquelle NVIDIA AI
Das gilt gleichermaßen auch für Server-CPUs zur Orchestrierung von Trainingsprozessen sowie Datenlade-, Protokollierungs-, sowie Augmentations-Vorgängen. Wenn die CPUs nicht mit der GPU-Performance Schritt halten können, bleiben sie unausgelastet. NVIDIA berichtet (2), dass dies für Samsung Research zu einem so großen Problem wurde, dass sie mit der Migration von Daten-Augmentations-Pipelines auf die GPUs selbst begonnen haben, obwohl das die verfügbaren GPU-Ressourcen für das neuronale Netzwerk selbst reduzierte (Quelle: Goyal, P., Dollár, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., … & He, K. (2017). Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv preprint arXiv:1706.02677). Das CPU-RAM sollte deshalb rund 2x - 3x den Umfang des GPU-Speichers besitzen.
Ein Fazit: Der zentrale Datenengpass liegt bei KI derzeit auf der Speicherebene, um den geforderten höchsten Durchsatz (IOPS, GB/s) bei möglichst niedrigen Latenzen zu liefern. Storage-Systeme, die handelsübliche SSDs mit seriellen Schnittstellen (SATA, SAS) verwenden, stoßen da an ihre Leistungsgrenzen. NVMe und NVMeF (fabrics) sind die geeigneten Technologien-/Protokolle für den schnellen Data Storage.
Zu beachten ist ferner, dass bei Deep Learning / Machine Learning zwar der Data Ingest ein relativ einfaches Streaming von sequentiellen Schreibvorgängen impliziert, die weiteren Prozesse jedoch aus vielen kleinen zufälligen Lese-Operationen bestehen können. KI zur Mustererkennung beim Datenzugriff selbst, um die Daten schon in den Cache zu holen, bevor sie benötigt werden, ist hier hilfreich. Für die Archivierung der „kalten“ Daten sollten die Daten dann automatisiert auf Basis definierter Richtlinien weiter in den Objekt-Storage-Bereich (on-prem/Cloud) verschoben werden.
Querverweise / weiterführende Informationen:
(1) Link > McKinsey Studie zu Künstlicher Intelligenz: Größeres Potenzial als die Dampfmaschine
Link > Sizing the prize What’s the real value of AI for your business and how can you capitalise? PWC 2017, 170905-115740-GK-OS.
(2) NVIDIA Link > Training AI for Self-Driving Vehicles: the Challenge of Scale
Link > Speicherlösungen für autonome Fahrzeuge: AutonomouStuff und Quantum kooperieren
Link zu unserem Beitrag > KI, Deep Learning & Storage am Beispiel von Cambridge Consultants, NetApp und NVIDIA
Link > Pure Storage FlashBlade und NVIDIA DGX-1: KI-optimierte Infrastruktur für Deep Learning
Hinweis > Vorankündigung Fujitsu Storage Days 2019 - Neueste Entwicklungen aus dem Bereich Storage für Ihr Rechenzentrum.