Houston (TX), Starnberg, 02. Mai 2022 - Lösung für Deployment- und Monitoring; neues HPE Machine Learning Development System verkürzt die Zeit bis zum Produktiveinsatz...
Zur Ankündigung: Hewlett Packard Enterprise bringt ein Komplettsystem auf den Markt, das die Entwicklung und das Training von KI-Modellen drastisch beschleunigt soll. Das HPE Machine Learning Development System umfasst eine Softwareplattform für das maschinelle Lernen, HPC-Systeme, Beschleuniger, Netzwerke und Systemmanagement. Die ML-Software stammt aus der Übernahme von Determined AI und wurde inzwischen in HPE Machine Learning Development Environment umbenannt. Das HPE Machine Learning Development System ist laut Anbieter ab sofort weltweit verfügbar.
Zu den Pilotanwendern gehört das deutsche Startup Aleph Alpha – es trainiert mit dem neuen HPE-System sein multimodales KI-Modell, das Natural Language Processing (NLP) und Computervision verbindet. Das Modell kombiniert Bild- und Texterkennung für fünf Sprachen mit einem menschenähnlichen Kontextverständnis. Nach der Bereitstellung des Learning Development Systems konnte Aleph Alpha nach vorliegenden Angaben in Rekordzeit mit dem Training beginnen. Zum Einsatz kommen dabei hunderte von GPUs.
Anwenderzitat Jonas Andrulis, Gründer und CEO von Aleph Alpha: „Das HPE Machine Learning Development System gibt uns eine erstaunliche Effizienz und eine Leistung von mehr als 150 Teraflops. Das System wurde schnell aufgesetzt, und wir konnten mit dem Modell-Training innerhalb von Stunden anstatt erst nach Wochen beginnen. Angesichts unserer gewaltigen Workloads und unserer laufenden Forschungstätigkeit ist es ein großer Vorteil, sich auf eine integrierte Lösung für Deployment und Monitoring verlassen zu können“.
Komplexität der KI-Infrastruktur reduzieren
Nach Untersuchungen von IDC haben Unternehmen in Bezug auf KI-Infrastruktur im Schnitt einen niedrigen Reifegrad. Das sei oft der Grund für das Scheitern von KI-Projekten. In der Regel erfordere die Einführung einer KI-Infrastruktur einen komplexen, mehrstufigen Prozess, der den Kauf, die Einrichtung und Verwaltung eines hochgradig parallelen Software-Ökosystems und einer maßgeschneiderten Infrastruktur umfasst. Das HPE Machine Learning Development System kann Unternehmen dabei unterstützen, diese Komplexität zu reduzieren; ferner soll es dazu beitragen, die Genauigkeit der Modelle durch verteiltes Training, automatische Hyperparameter-Optimierung und Neural Architecture Search zu verbessern.
Das System beinhaltet eine integrierte & vorkonfigurierte KI-Infrastruktur, die laut Entwickler sofort eingesetzt werden kann. Als Teil des Angebots bietet HPE Pointnext Services eine Vor-Ort-Installation und ein Software-Setup.
Das System ist als kleines Basismodul mit Erweiterungsoptionen verfügbar. Dieses Modul enthält laut Anbieter folgende Elemente:
- Das HPE Machine Learning Development Environment, womit Unternehmen Modelle schnell entwickeln, iterieren und skalieren können – von der Testphase bis zur Produktionsreife
- Das HPE Apollo 6500 Gen10 Plus System, das Rechenkapazität zum Trainieren und Optimieren von KI-Modellen bietet und mit 8 Tensor-Core-GPUS von NVIDIA mit 80 GB Arbeitsspeicher bestückt ist
- Systemmanagement mit der Software HPE Performance Cluster Management, dem Server HPE ProLiant DL325 und 1Gb-Ethernet-Switches (HPE) Aruba CX 6300
- Hochgeschwindigkeitsübertragung mit NVIDIA Quantum InfiniBand (1).
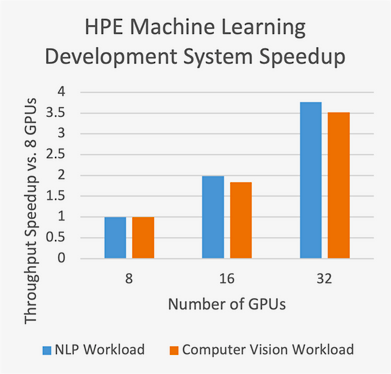
Abb. 1: Das HPE Machine Learning Development System wurde mit einem führenden Public Cloud-Anbieter verglichen, wobei ein Standardinstanz-Typ mit NVIDIA 8xA100-GPUs verwendet wurde, eine ähnliche Konfiguration wie die Apollo 6500 Gen 10 Plus-Systeme, die als Baustein für das HPE Machine Learning Development System dienen.
Quelle / Link > HPE Blogpost > HPE Machine Learning Development System: Real-world NLP & computer vision model benchmarks. Evan Sparks, VP of HPC & AI at HPE.
(1) Quelle / Abbildung: NVIDIA Quantum-2 InfiniBand
Link > https://www.nvidia.com/en-us/networking/
Die NVIDIA Quantum-2 InfiniBand Plattform bietet proaktive Überwachung und Congestion Management, um den Datenverkehr zu isolieren, Performance-Jitter nahezu zu eliminieren und eine vorausschauende Performance zu gewährleisten, so als ob die Anwendung auf einem dedizierten System ausgeführt würde.
Querverweis:
Unser Beitrag > YouGov-HPE Umfrage: Zwei Drittel der Vorstände in D.A.CH haben keine Datenstrategie
Unser Beitrag > appliedAI deutsche KI-Start-up Landkarte 2022