Cambridge (UK), Starnberg, 13. Sept. 2018 - Warum KI neben Hochleistungs-Prozessoren wie GPUs ein schnelles und umfassendes Speichermanagement benötigt...
Zum Hintergrund: Anfang dieser Woche fand in den Research-Labs von Cambridge Consultants / Cambridge (UK) eine exklusive Informationsveranstaltung - gemeinsam organisiert von NetApp, Cambridge Consultants und NVIDIA - statt. Das Storage Consortium war vor Ort und hatte die Gelegenheit, mehrere KI-Demos von Cambridge Consultants auf Grundlage von NetApp- und NVIDIA-Technologie live zu erleben, danach selbst auszuprobieren und mit den anwesenden Experten zu diskutieren. Eine Erkenntnis daraus schon mal vorab: KI selbst ist keine eigene Industrie (und „not a meaning in itself“), soll aber nach Ansicht der Experten künftig einen unverzichtbarer Teil aller wesentlichen Unternehmens-Anwendungen und damit der Industrie / Forschung darstellen; dies betrifft dann auch das Daten-Management.
Die dort gezeigten und von Cambridge Consultants entwickelten KI-Demos gaben einen anschaulichen Einblick zur derzeitige Leistungsfähigkeit von AI-Systemen und deren Entwicklung (Hardware, Software) und adressierten zudem (auf den ersten Blick) einige teils ungewöhnliche Fragestellungen:
Kann die KI eine menschliche Skizze in ein fertiges "Kunstwerk" verwandeln, fast so, als wären Van Gogh, Cézanne und Picasso „in der Maschine“?
Ist Deep Learning in der Lage, an dem Punkt wo das menschliche Sehen versagt, Bilder wiederherstellen, die es noch nie zuvor gesehen hat bzw. wenn nur teilweise Daten vorhanden sind? (siehe Abb. 1 unten)
Wie schnell und genau funktioniert die selbständige Mustererkennung von KI-basierenden, intelligenten ML/DL /NLP-Algorithmen (Advanced AI) gegenüber der bisherigen Regel-basierten (menschlich-beinflussten) Programmierung (traditionelle KI), hier am Beispiel der Musik-Stil-Erkennung?
Bei den vorhandenen Beispielen kann es sich aber auch um Trainingsdaten für die Bild- oder Mustererkennung für Predictive Maintenance (PM) bzw. autonomes Fahren handeln, oder aber um Transaktions- oder Forschungsdaten, die in einem (Big) Data Warehouse abgespeichert werden.

Abb. 1 Quelle: Cambridge Consultants / Digital Greenhouse - In-house AI Lab aus "Deep Ray" Bilderkennungs-Projekt (Foto: Storage Consortium)
Wo liegt der gemeinsame Nenner zwischen KI, modernen Anwendungen wie IoT und Storage ?
Der direkte Schnittpunkt zwischen künstlicher Intelligenz und modernen Anwendungen sind natürlich die Daten, denn Themen wie IoT oder Big Data Analytics werden die Datenmenge künftig exponentiell vergrößern. Für Unternehmen sind Daten aber nur dann wertvoll, wenn sie auch in einen sinnvollen Zusammenhang gestellt werden können. Hier setzt KI an, denn alle wesentlichen Elemente dieses Ökosystems wie auch die Bereiche Robotik, Sensorik, Speicherverwaltung, Netzwerke etc. müssen durch KI unterstützt werden. Folgt man diversen Studien, soll dieser Trend in wenigen Jahren bei vielen Unternehmen bereits über deren Wettbewerbsfähigkeit entscheiden. Einer PWC-Analyse** zufolge werden jedenfalls neue Technologien ihr volles Potenzial erst dann entwickeln können, wenn die Unternehmen in der Lage sind, das Internet der Dinge mit den Möglichkeiten der Künstlichen Intelligenz zu verknüpfen.
**Querverweis & Quelle: > Sizing the prize What’s the real value of AI for your business and how can you capitalise? PWC 2017, 170905-115740-GK-OS, http://www.pwc.com/AI
Rechenleistung und I/O-Performance von Speichersystemen - Maschinelles Lernen ist komplex und datenintensiv
Es erfordert grundsätzlich sehr viel Rechenleistung, um das heutige maschinelle Lernen zu verarbeiten. Traditionelle x86-basierte Server, unterstützt durch Festplatten-basierte Speicher-Arrays und Network Attached Storage (NAS, SAN) kommen schnell an ihre Leistungsgrenzen, wenn es darum geht, modernste Lern-Algorithmen auszuführen. Dafür wurden die gleichen Server und Speichernetzwerke, die klassische geschäftskritische Anwendungen ausführen, nicht konzipiert.
Die Latenzen und der Durchsatz der Speichersysteme, in denen die Daten gespeichert sind, wirken sich direkt auf die Leistung des KI/ML-Gesamtsystems aus (balanced system). Der zentrale Datenengpass liegt dabei auf der Speicherebene und der Fähigkeit, höchsten Durchsatz (IOPS, GB/s) bei möglichst niedrigen Latenzzeiten zu liefern. Laut Carlo Ruiz, EMEAI Business Manager DGX | NVIDIA Corporation, sind NVIDIAs GPU-basierte Lösungen heute in der Lage, bestimmte Algorithmen fast 100 mal schneller zu trainieren als herkömmliche CPU-Lösungen. Moderne Implementierungen von maschinellem Lernen sind damit stark auf GPU-basierte parallele Berechnungen angewiesen und diese wiederum benötigen einen extrem schnelle Speicherlösung (DRAM, Flash).

Abb. 2: Das Bild zeigt eine NVIDIA GV-100 GPU graphic processing unit (Foto: Storage Consortium, NDeuschle, Sept. 2018)
Querverweis: NVIDIA Blog > Training AI for Self-Driving Vehicles: the Challenge of Scale
Ein weiterer Punkt beim Thema Latenzen betrifft den Abruf von Daten über größere Distanzen. Die Daten müssen die Verbindung zwischen dem Verarbeitungsknoten und der Speicherlösung durchqueren, was zu einer weiteren Latenzzeit-Erhöhung führt.
Viele Storage-Systeme, die handelsübliche SSDs verwenden, stoßen daher schnell an Leistungsgrenzen, falls serielle Schnittstellen (SATA, SAS) verwendet werden. NVMe und NVMeF (fabrics) sind hier deshalb die geeigneten Technologien-/Protokolle für den schnellen Data Storage und die Zukunft gegenüber SCSI. Zu beachten ist ebenfalls, dass bei ML/DL zwar der Data Ingest ein relativ einfaches Streaming von sequentiellen Schreibvorgängen impliziert, die weiteren Prozesse jedoch aus vielen kleinen zufälligen Lese-Operationen bestehen können (KI zur Mustererkennung beim Datenzugriff selbst, um diese schon in den Cache zu holen, bevor sie benötigt werden, ist hier sehr hilfreich).
Ein weiteres Problem bei der Nutzung der Public Cloud für maschinelles Lernen besteht darin, dass die Latenz weiter erhöht wird und das Data Management sich je nach Art der verwendeten Lösung deutlich verkomplizieren kann.
Wie diskutiert, ist Deep Learning ein sehr anspruchsvoller KI-Workflow in Bezug auf Rechenleistung und I/O; somit kann eine für Deep Learning konzipierte Datenpipeline auch andere KI- und große Daten-Workflows bewältigen. Nach Ansicht von Christian Lorentz, Senior Product Marketing Manager EMEA bei NetApp, liefern die NetApp All Flash FAS (All Flash Storage) hohe Leistung und Kapazität und reduzieren gleichzeitig den Bedarf an zeitraubenden Datenkopien.
NetApp arbeitet nach eigenen Angaben ferner an der weiteren Bereitstellung von NVMe over Fabrics (NVMe-oF) und seines Plexistor-Angebotes, um seine All-Flash-Funktionen weiter auszubauen. Für die Archivierung kalter Daten migriert die NetApp FabricPool-Technologie Daten automatisch auf Basis definierter Richtlinien in den Objekt-Storage. Die NetApp Data Fabric liefert für die geschilderten weiteren Data Management Herausforderungen jedenfalls die notwendige Technologie-Optionen, um die Anforderungen der gesamten Deep-Learning-Pipeline zu erfüllen, vom Edge über den Kernbereich bis hin zur Cloud.
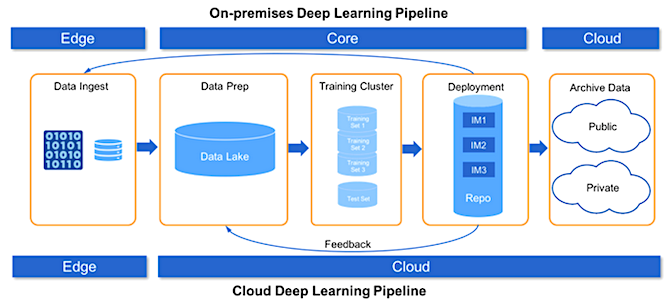
Abb. 3: On-Premises Deep Learning Pipeline (Bildquelle: NetApp, Addressing AI Data Lifecycle Challenges with Data Fabric, Santosh Rao)
Quelle & Querverweis: NetApp Blog > Choosing an Optimal Filesystem and Data Architecture for Your AI/ML/DL Pipeline