München, Starnberg, 09. Jan. 2019 - Technologie-Trends wie KI oder das Internet of Things (IoT) sind bekannte Größen, die jedoch das Datenmanagement neu definieren…
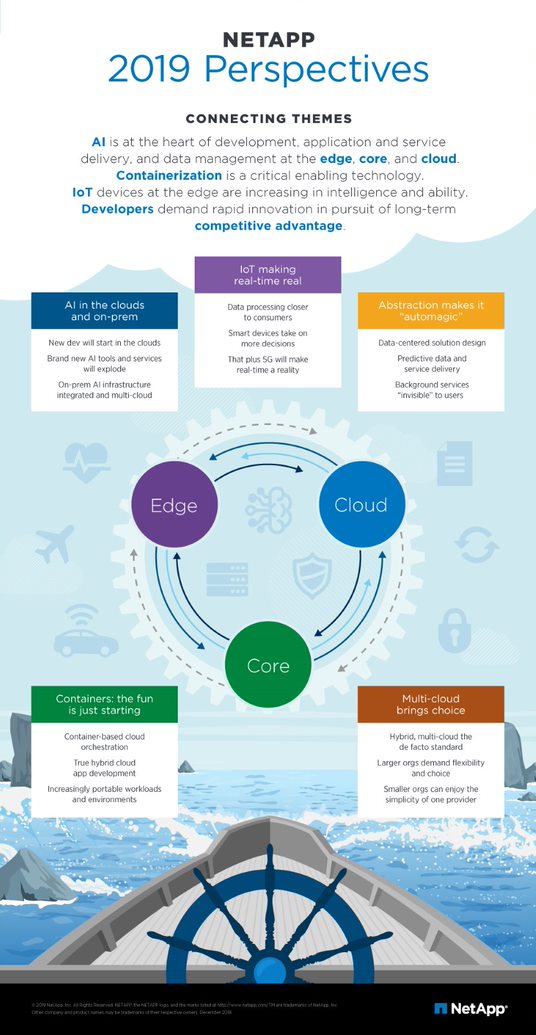
Zum Hintergrund: Folgt man Atish Gude, Chief Strategy Officer (CSO) bei NetApp (1), können Entwickler mit Containern und intelligenteren IoT-Edge-Geräten - unterstützt von KI und Cloud Computing - im kommenden Jahr die nötigen Impulse für einen datengetriebenen Markterfolg und neue Geschäftsmöglichkeiten setzen. Je mehr sich die IT-Infrastruktur von On-Premise-Systemen und -Servern löst, umso mehr wird es dabei aber darauf ankommen, das Speicher- und Datenmanagement hochgradig verlässlich und verfügbar zu gestalten. Statt geschlossener Systeme sind die modernen Architekturen zunehmend ein abstraktes Netz aus cloudbasierten Lösungen und Services, oder anders formuliert, eine hybride Multi-Cloud Data Fabric; und um so wichtiger wird damit ein einheitliches, vereinfachtes Datenmanagement über lokale- und Cloud-Umgebungen hinweg, das robust und hochverfügbar funktioniert.
1) KI-Sprungbrett Cloud
Auch wenn wir gerade erst an der Oberfläche des KI-Potenzials kratzen, stehen immer mehr Software-Tools zur Verfügung, die – unterstützt durch die Rechenpower der Cloud – die Entwicklung von KI-Applikationen zugänglicher machen. Diese KI-Lösungen werden zum einen die nötige Performance und Skalierbarkeit für On- oder Off-Premises-Integration bieten. Zusätzlich stellt ihr Variantenreichtum auch die Unterstützung zahlreicher Datenzugriffsprotokolle und Dateiformate sicher – die entsprechende IT-Infrastruktur vorausgesetzt. Denn im KI-Bereich muss diese schnell, verlässlich und automatisiert sein, um die entstehenden Workloads schultern zu können. Diese Architekturen bereitzustellen, wird die nächste große Herausforderung werden.
2) Das IoT-Edge wird selbstständiger
Bisherige IoT-Geräte folgten dem „Nach Hause telefonieren“-Prinzip: Ihre Sensoren sammeln Daten, schicken diese zur Analyse weiter und warten auf weitere Instruktionen. Aber selbst mit dem kommenden 5G Netz stehen diese Datenwege - in die Cloud oder das Rechenzentrum und wieder zurück - notwendigen Entscheidungen in Echtzeit im Weg; zusätzlich steigen die Datenmengen. Das verlagert die Datenverarbeitung Richtung Anwender bzw. deren Endgeräte. Deshalb werden immer mehr IoT-Geräte inhärente Kapazitäten für die Verarbeitung und Reduzierung ihrer gesammelten Daten enthalten. Das erlaubt beispielsweise die Vorselektion relevanter Daten direkt im Gerät, das selbstständig entscheidet, welche Daten an Cloud oder Arbeitsplätze weitergeleitet werden. Für Nutzer bedeutet das einen schnelleren Zugriff auf die Datensätze, die für ihre Arbeit wichtig sind, und eine Beschleunigung datengestützter Entscheidungsprozesse.
3) Einmal automagisch, bitte
Je mehr sich die IT-Infrastruktur von On-Premises-Systemen und -Servern löst, umso wichtiger ist es, dass das Speicher- und Datenmanagement hochgradig verlässlich und verfügbar ist. Statt geschlossener Systeme sind die modernen Architekturen ein abstraktes Netz aus cloudbasierten Lösungen und Services – also Hybrid-Multi-Cloud Data Fabric statt Rechenzentrum. Dank Containerisierung und Hybrid-Cloud-Umgebungen müssen sich Entwickler nicht mit den Bestandteilen des Systems auseinandersetzen, sondern können voraussetzen, dass es eigenständig und automatisch funktioniert. Dies kommt der veränderten Erwartungshaltung der Entwickler an die IT-Infrastruktur entgegen – sie soll einfach funktionieren, eben „automagisch“. Neuer Faktor dieser zunehmend dynamischen Konstrukte werden prädiktive Technologien und Analysen sein, die Entwicklern und Entscheidern gleichermaßen helfen, fundierte Rückschlüsse aus ihren Daten zu ziehen.
4) Die Frage nach der „richtigen" Cloud
In der Theorie werden Daten und Workloads dank der Cloud mobiler und damit ungebundener. Ganz praktisch stehen Unternehmen vor der Herausforderung, bei ihrem Datenmanagement die Balance zwischen vielen konkurrierenden Faktoren zu halten: Datensicherheit, Zugriffszeiten und Portabilität unterschiedlicher Services, um nur einige zu nennen. Und viele dieser Elemente unterliegen den Beschränkungen des jeweiligen Providers, Stichwort Platform- oder Vendor-lock-in. Gerade für kleinere Unternehmen ist deshalb die Einfachheit und Optimierung eines einzelnen Anbieters verlockend. Komplexere Unternehmensstrukturen großer Konzerne erfordern wiederum eine Flexibilität und Service-Vielfalt, die nur Hybrid-Multi-Cloud-Umgebungen bieten können. Deren Kosteneffizienz ist ein weiteres Plus. Egal welchen Weg ein Unternehmen allerdings in die Cloud wählt, es war nie wichtiger, eine ganzheitliche Datenstrategie zu entwickeln, um das optimale aus der gewählten Infrastruktur herauszuholen.
5) Containerisierung: Freiheit für Workloads
Der Einzug der Containerisierung verspricht eine Hybrid-Cloud-Entwicklungsumgebung ohne Vendor-lock-in, die ihr Potenzial maximal ausschöpft. Dank De-facto-Standard Kubernetes für Multi-Cloud-Applikationen steht einem intuitiven Workload-Management nichts mehr im Wege. Vorteil: Neue Cloud-Orchestrierungstechnologien, die auf Containern basieren, ermöglichen mehr Anwendungsfälle sowohl für Public- als auch On-Premises. Workloads können nun direkt an die Datenquellen verlagert werden, nicht wie bisher umgekehrt. Das fördert eine agile Entwicklungsumgebung und macht Schluss mit dem ständigen Umziehen von Applikationen – letztlich eine doch sehr angenehme Entwicklung.

Das Foto zeigt Atish Gude, Chief Strategy Officer bei NetApp (Bildquelle: NetApp)
| Anhang | Größe |
|---|---|
| 97.53 KB |
{kind=link}