Starnberg, 31. Juli 2017 - Weshalb die digitale Transformation nach einer neuen Generation von integrierten & hochleistungsfähigen Speicher- und Computearchitekturen verlangt...
Um was es in diesem Blogbeitrag geht: Eine direkte Verbindung zwischen künstlicher Intelligenz (KI) und dem Internet der Dinge (IoT) sind die Daten. Durch IoT, Autonomes Fahren, Machine- und Deep Learning (ML, DL) - alles Elemente der Digitalen Transformation - werden die Datenkapazitäten, welche Unternehmen künftig verarbeiten, deutlich vergrößert. Nur, was machen die Firmen und Organisationen mit diesen Datenbergen? Schon spricht man in Anlehnung an die Kosmologie (dunkle Materie) von Dark Data, also stetig wachsenden Bergen von Bits-& Bytes, meist ohne Klassifizierung bzw. Struktur (unstructured data). Hier kommt die künstliche Intelligenz zum Einsatz, weil nur über eine sinnvolle Korrelation und Verbindung der Daten aus z.B. Sensoren, Robotiksystemen und diversen Cloud-Apps sich der wirtschaftliche Nutzen und Vorteil der Digitalisierung einstellen wird.
Es gibt zwischenzeitlich viele Beispiele, wie die Industrie von KI und Big Data profitiert und damit auch beginnt, sich selbst zu transformieren. Skalierbarer Storage - auch wenn er auf den ersten Blick hierbei nicht im Vordergrund steht - spielt dabei fast immer eine Schlüsselrolle. Nicht nur aus Gründen der Leistungsfähigkeit (Durchsatz, I/O) sondern auch im Sinne der Wirtschaftlichkeit (OPEX, CAPEX).
Software Definierter Speicher kann ein wichtiges Element zur Kostenkontrolle darstellen, denn eine zentrale und einheitliche Verwaltungsinstanz über den Hardwaresystemen reduziert den Management Overhead.
Der Trend zu hochspezialisierten und dedizierten Compute- und Speichersystemen, die lokal angeschlossen (DAS = direct attached storage) oder als Appliances betrieben werden, ist sichtbar, aber es entstehen damit leicht hochkomplexe Inseln. Gefordert sind Applikationsseitig massiv skalierbare (parallele) Filesysteme und flexible (logisch) integrierbare Speicheranwendugen, die neben hoher Leistung über einfache Verwaltungstools und einen hohen Automatisierungsgrad zu niederigen Kosten (OPEX) verfügen. DAS als direkt angeschlossener und über n-Server verteilter Speicher liefert für moderne Data Analytics Workloads wie Deep Learning (DL) und Hadoop Cluster nur eine begrenzte Verfügbarkeit und Skalierung.
Granular skalierbare (Flash) Storage Pools mit Block- /File und Object Access, die mit Technologien wie NVMe (over Fabrics) sowie kapazitätsoptimierenden Tools eine massiv parallele I/O-Architektur bei geringster Latenz liefern, gehören aus meiner Sicht die Zukunft.
NAND Flash, NVMe + (RDMA) Fabrics, SDS, Object Storage mit Hochleistungs HDDs, InfiniBand, 25G / 40 / 50 G / 100 G Ethernet (Ethernet = #1 im Hyperscale Cloud Umfeld) liefern dafür die breite technologische Basis und werden so zu Eckpfeilern in Bezug auf die künftige Wettbewerbsfähigkeit von Unternehmen und Organisationen.
Aber bislang gilt "Software zieht Hardware": Je leistungsfähiger die CPU-Seite (Beispiel: NVIDIA DGX-1 Deep Learning Compute Appliance anstelle ca. 250 x Standard x86-Server CPUs), desto anspruchsvoller die App-Entwicklung. Dann wird eine neue Storage Generation notwendig, die Kosteneffizienz mit niedriger Latenz und hoher Bandbreite kombiniert. Weitere Randbedingungen betreffen die Energieeffizienz und eine robust hohe Temperaturbeständigkeit (z.B. im Autoeinsatz) bei höchster Leistung.
Ein Blick in die Zukunft: Die skizzierten und rasch fortschreitenden Entwicklungen bei Big Data, Deep Learning / künstliche Intelligenz, verlangen idealerweise also nach hochspezialisierten Systemen, die Compute- und Data Storage innerhalb einer High-density-Architektur kombinieren, ohne dabei jedoch isoliert innerhalb der IT-Infrastruktur agieren zu müssen. Ein vom MIT und der Stanford University vorgeschlagener Weg - siehe Abb. 1 unten - einer neuen, nicht auf CMOS beruhenden 3-D Nano Chip basierten Compute-/Speicherarchitektur (Kohlenstoff-Nano-Röhrchen / 2-D non-volatile Resisitive Random Access Memory / RRAM = Storage Class Memory) in Verbindung mit herkömmlichen Schaltkreisen auf Siliziumbasis könnte künftig die Brücke zwischen hochspezialisierten Systemen und kommerziellen Standardapplikationen im Sinne einer integrierten (software-definierten) Hardware-Plattform bilden.
Fazit: Leistungsfähige Hardware- und Softwaregesteuerte Infrastrukturen bilden immer mehr das zentrale Element eines Unternehmens, ohne die alle geschäftlichen Initiativen im Zusammenhang mit der Digitalisierung künftig nicht zu realisieren sind.
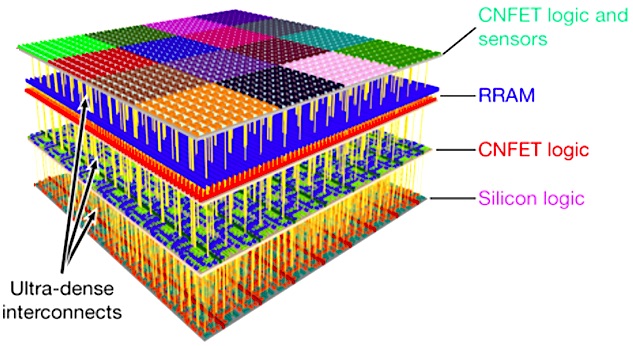
Abb. 1 Bildquelle: Gestapeltes 3D Chip Design kombiniert Computing und Data Storage (Quelle: Nature, 547, 74–78 / 06 July 2017)**
Die vier vertikale Schichten im Stanford / MIT 3D Nano Chip:
1. NanoCarbon-Tube Feldeffekt Transistoren (CNFET) mit Sensoren (Input); 2. RRAM non-volatile; 3. CNFET Sensor data-classification Logic; 4. MOS-FET Layer zur möglichen Integration in herkömmliche Compute-Umgebungen.
**Quelle: Nature, Three-dimensional integration of nanotechnologies for computing and data storage on a single chip. Max M. Shulaker, Gage Hills, Rebecca S. Park, Roger T. Howe, Krishna Saraswat, H.-S. Philip Wong & Subhasish Mitra.