München, Starnberg, 22. Mai 2019 - Cloud-native Containerlösungen an Stelle von virtuellen Maschinen verlangen nach einem hierfür optimierten Speichermanagement...
Zum Hintergrund: Die letzte von der Cloud Native Computing Foundation im August 2018 durchgeführte halbjährliche CNCF Umfrage unter über 2000 IT-Profis aus Nordamerika und Europa zum Thema "Container- und Kubernetes im produktiven Einsatz" ergab, dass 75% der Befragten bereits Container in der Produktion verwenden, während die verbleibende Anzahl plant, sie in Zukunft zu nutzen. Die Nutzung der Kubernetes-Plattform ist mit 83% (vorher 77%) dabei stark, die Nutzung der Plattform erfolgt bei den Befragten zu 58% in der Produktion.
Persistent Storage für zustandsabhängige Anwendungen ist derzeit noch ein Hindernis, wenn es um eine breitere Akzeptanz von Containern im Unternehmen geht. Daten Management Spezialist NetApp konnte auf Grund der StackPointCloud Übernahme (1) mit Trident als einer der ersten Anbieter eine robuste - auf open-source Technologie - basierende Container Storage Lösung bieten, um diese spezifischen Anforderungen zu adressieren. Trident als dynamischer Speicher-Orchestrator schafft die Möglichkeit, Speicherressourcen über Storageplattformen hinweg zu verwalten. Die Lösung integriert sich nativ in Kubernetes, um persistente Volumenanforderungen bei Bedarf zum Zeitpunkt der Anforderung dynamisch bereitzustellen; zusätzlich existiert eine REST-Schnittstelle, die von jeder Anwendung verwendet werden kann, um Speicherplatz über die konfigurierten Ressourcen hinweg zu erstellen und zu verwalten (https://github.com/netapp/trident)
Auch das open source Projekt Rook - initiiert vom Speicher- und Data Management Spezialisten Quantum Corp. - konzentriert sich auf Cloud-natives Container Management, Terminierung und Orchestrierung. Rook verwandelt hierzu verteilte Storage-Software in sich selbstverwaltende, hochskalierende und selbstheilende Speicherdienste. Entwickelt für Kubernetes und andere Cloud-native Umgebungen nutzt Rook dabei Erweiterungspunkte und ermöglicht Lifecycle Management, Ressourcenmanagement, Sicherheit und Überwachung. Mit Rook sollen Unternehmen ihre Rechenzentren mit dynamischer Anwendungsorchestrierung für verteilte Storage-Systeme modernisieren können, die in lokalen Cloud-nativen Umgebungen betrieben werden (https://github.com/rook/rook).
Rook bringt dazu Datei-, Block- und Objektspeichersysteme in den Kubernetes-Cluster und führt sie mit anderen Anwendungen und Diensten zusammen, die den Speicher verbrauchen (s.a. Abb. 1 unten). Dadurch wird der Cloud-native Cluster autark und portabel über Public Clouds und On-Premise-Bereitstellungen hinweg. Das Projekt wurde entwickelt, um Unternehmen in die Lage zu versetzen, ihre Rechenzentren mit dynamischer Anwendungsorchestrierung für verteilte Speichersysteme in lokalen und öffentlichen Cloud-Umgebungen zu modernisieren.
Anstatt ein völlig neues Speichersystem zu bauen, konzentriert sich Rook darauf, produktiv erprobte Speichersysteme wie Ceph als verteilte Storagelösung in eine Reihe von Cloud-basierten Diensten zu verwandeln, die auf Kubernetes laufen. Rook integriert sich dabei tief in die Orchestrierungslösung und bietet Funktionen zu Themen wie Sicherheit, Richtlinien, Quoten, Lifecycle Management oder Ressourcenmanagement. Dazu wird im wesentlichen das „Operator-Pattern“ genutzt, um Kubernetes zur Unterstützung von Speichersystemen zu erweitern. Es wurde nach Angaben der Entwickler-Community ein Konzept für einen Speichercluster, Speicherpool, Objektspeicher und Filesystem hinzugefügt, um welche Kubernetes erweitert wurde.
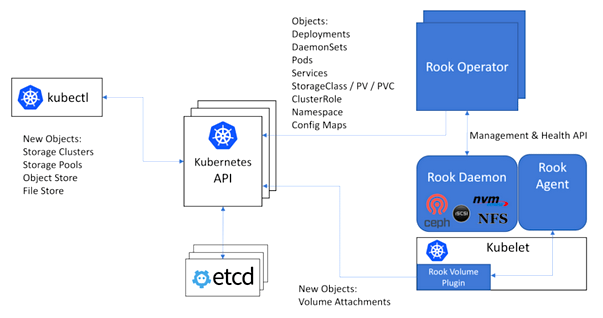
Abb. 1: CNCF to Host the Rook Project to Further Cloud-Native Storage Capabilities (Bildquelle: Cloud Native Computing Foundation, CNCF)
Link > https://www.cncf.io/blog/2018/01/29/cncf-host-rook-project-cloud-native-storage-capabilities/
Welche Anwendungsbereiche profitieren davon?
Industrie 4.0 Initiativen mit Shop Floor 4.0 erfordern eine effiziente und vertikale Vernetzung der Geschäftsprozessebene mit produktionsnahen Systemen, Mess- und Steueraggregaten. Beispiel: das aktuelle Fraunhofer IESE BaSys 4.0 als Open Source Projekt fungiert als Betriebssystem, das Produktionsanlagen miteinander sowie mit Planungs- und Steuerungssystemen vernetzt. Das System sorgt dafür, dass sich Fertigungsprozesse flexibel an sich verändernde Bedingungen z.B. durch ein neues Produkt, anpassen lassen. Das IESE hat in diesem Zusammenhang einen Standard für die Machine-to-Machine-Kommunikation entwickelt, damit diese die gleiche Sprache sprechen können. Um die Daten hochverfügbar zu halten, müssen sich dazu verschiedene Datenquellen wie Datenbanken und Anwendungen überall dort, wo diese verwendet werden - vor Ort oder in der Cloud - lesen, verarbeiten und reproduzieren lassen.
In diesem Umfeld kommen Container anstelle virtueller Maschinen (VMs) zum Einsatz, d.h. eine persistente Speicherlösung unter Kubernetes zur Vereinfachung und Automatisierung des persistenten Container Storage wird zentral. Vorteile: manuelle Ticket für die Bereitstellung entfallen und das Self-Service-Speicher- und Datenmanagement in der Sprache des Containers ist gewährleistet. (2)
Hinweis: Information aus erster Hand erhalten Sie hierzu auch im Rahmen unserer kommenden Anwendertagung am 25. Juni 2019 in Frankfurt/Main unter dem Motto: "Leistungsfähige Datenverwaltungs- und Speicherinfrastrukturen für Rechenzentren".
Querverweise, Quellen & weitere Informationen:
Blogpost > Storage- und Daten Management im Zusammenhang mit DevOps und Container Storage
(1) Storage Consortium Podcast zu StackPointCloud
(2) Unser Beitrag > Persistent Storage für Docker Container und Shop Floor 4.0
| Anhang | Größe |
|---|---|
| 71.41 KB |
{kind=link}