Düsseldorf, Starnberg, 03. Dez. 2019 - Insbesondere hinsichtlich der Datennutzung müssen für ML- und KI-Daten zuerst die geeignete Rahmenbedingungen geschaffen werden...
Zum Hintergrund: VDI veröffentlichte den neuen Statusreport „Maschinelles Lernen – Künstliche Intelligenz mit neuronalen Netzen in optischen Mess- und Prüfsystemen“. (1) Die industrielle Bildverarbeitung (BV) in Deutschland blickt auf ein jahrzehntelanges Wachstum mit zuletzt 2,8 Mrd. Euro Umsatz im Jahr 2018 zurück. Immer häufiger besteht in der Industrie der Bedarf, die erzeugten Bilddaten automatisiert zu bewerten, sei es zur Prozess- und Qualitätskontrolle oder in der medizinischen Diagnostik. Mit dem neuen Statusreport will der VDI nach eigenen Angaben in das maschinelle Lernen für optische Mess- und Prüfsysteme einführen und die Potenziale des maschinellen Lernens vorstellen.
Nach Ansicht des VDI müssen insbesondere hinsichtlich der Datennutzung erst geeignete Rahmenbedingungen geschaffen werden. VDI-Kommentar: "Große Datenmengen müssen zuverlässig gesichert, zwischen Projektpartnern ausgetauscht und vor unberechtigtem Zugriff gesichert werden können. Die Verfügbarkeit von industriellen Daten und die Freiheit zur Nutzung der Daten werden in naher Zukunft eine wesentliche Grundlage der wirtschaftlichen Souveränität eines Wirtschaftsraums bilden. Notwendig sind daher klare Regelungen, welche Eigentums- oder Nutzungsrechte an solchen Daten bestehen, wo die Grenzen individueller Rechte an Daten liegen und welche Rechte an den Ergebnissen von Lernverfahren für KI und ML bestehen. Diese Regelungen müssen in einem europäischen Rahmen vereinbart sein."
Die derzeitigen Technologietreiber für das maschinelle Lernen (ML) im Bereich der Bildverarbeitung sind demnach vor allem die Automobiltechnik, die Kommunikations- und Unterhaltungselektronik (Smartphones), die Medizin sowie der Bereich der öffentlichen Sicherheit. Das maschinelle Lernen zeigt dabei Stärken in klassischen Bildverarbeitungs-Aufgaben wie Segmentierung, Objekterkennung und Klassifikation. KI-Lösungen mit neuronalen Netzten eignen sich insbesondere für Aufgaben, für die sich weniger leicht Regeln angeben lassen, wie die Erkennung von Anomalien (in Bildern oder Zeitreihen) sowie bei der Fusion oder Korrelation von verschiedenen Datenströmen.
Zentrales Forschungsfeld in der BV ist die Erklärbarkeit der Ergebnisse des ML
Häufig kann die Frage „Warum hat das System so entschieden?“ noch nicht beantwortet werden, da viele Verfahren des ML keine Kennzahlen für die Zuverlässigkeit ihrer Ergebnisse liefern. Allerdings ist genau das die notwendige Voraussetzung, um die Akzeptanz bei Anwendern sicherzustellen – beispielsweise bei der Abnahme von Projektergebnissen, bei Zertifizierungen von Verfahren oder bei der Erstellung von Diagnosen in der Medizin. Es braucht geeignete Kennzahlen, die die Qualität des Ergebnisses einschätzen. Sie sind insbesondere dann wichtig, wenn aus einem Ergebnis sicherheitsrelevante Entscheidungen abgeleitet werden sollen. Die Publikation zeigt den momentanen Stand und versucht, künftige Entwicklungen abzuschätzen.
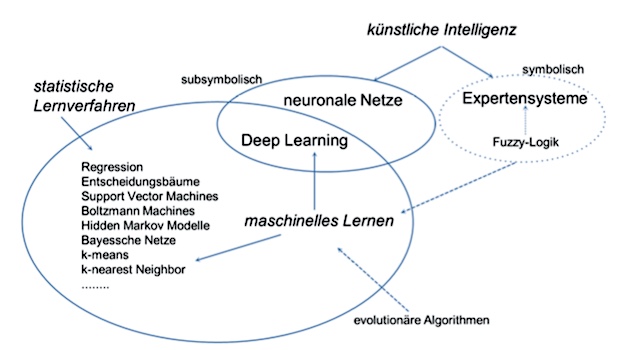
Abb. 1: Übersichtsgrafik zu den Verfahren / KI und ML (Bildquelle: VDI).
(1) Quelle: Der vollständige Statusreport „Maschinelles Lernen – Künstliche Intelligenz mit neuronalen Netzen in optischen Mess- und Prüfsystemen“ steht kostenfrei zur Verfügung unter vdi.de/publikationen
Bildquelle: VDI Statusreport (siehe oben).
Hier noch ein Hinweis zum Thema Data Science & Maschinelles Lernen für die Biomedizin und Wettervorhersage
Große und komplexe Datenmengen sind für die Wissenschaft der Alltag. Laut dem KIT sind aktuelle Methoden des Maschinellen Lernens und der Künstlichen Intelligenz bereits sehr effektiv darin, diese Daten für Prognosen zu nutzen. Das Projekt SIMCARD (steht für: Scalable and Interpretable Models for Complex And stRuctured Data), in dem das KIT mitarbeitet, soll neuartige Verfahren für das Maschinelle Lernen entwickeln, die robust und zuverlässig sind, dabei aber über einfache Vorhersagen hinausgehen. Dazu Melanie Schienle, Professorin für Ökonometrie und Statistik, zu SIMCARD am KIT: „Ziel ist es, mit passgenauen skalierbaren, fundierten und interpretierbaren Data-Science-Techniken Antworten auf drängende Probleme in vielfältigen Anwendungsbereichen zu liefern, insbesondere in der Biomedizin und der Wettervorhersage“.
Helmholtz investiert in innovative Information & Data Science Forschungsprojekte
Big Data und Künstliche Intelligenz bieten laut Helmholtz enormes Potenzial für alle gesellschaftlich wichtigen Bereiche, wie z.B. die Erforschung des Klimawandels, des Erdsystems und der Gesundheit. Als wichtiger Player im Bereich Information & Data Science finanziert Helmholtz nach eigenen Angaben nun in einer zweiten Runde zukunftsweisende Forschungsprojekte mit knapp 20 Millionen Euro. Nach einer erfolgreichen ersten Ausschreibungsrunde im Jahr 2017, in der bereits 17 Millionen Euro an Fördergeldern vergeben wurden, werden nun weitere Projekte des Helmholtz-Inkubators Information & Data Science gefördert. Diese erhalten nach vorliegenden Angaben insgesamt eine Finanzierung von knapp 20 Millionen Euro für einen Zeitraum von drei Jahren.
Link zu weiteren Information > https://www.helmholtz.de/forschung/information-data-science/information-data-science-pilot-projekte/pilotprojekte-2/
Querverweise zum Thema: