München, Starnberg, 02. Dez. 2019 - Gute Daten, schlechte Daten; wie Data Warehouse-Automatisierung helfen kann, die Datenintegrität von Big Data Apps zu gewährleisten...
Zum Hintergrund: Der Begriff Big Data wurde Mitte der 2000er Jahre eingeführt um Datensätze zu beschreiben, die zu groß waren, um sie mit herkömmlichen Business-Intelligence-Tools verwalten und verarbeiten zu können. Seitdem ist die Menge der Daten bekanntlich exponentiell weiter gewachsen und stellt IT-Manager allein schon wegen des riesigen Volumens vor zum Teil große Herausforderungen. Doch über die enorme Menge der Daten hinaus, gibt es noch weitere Facetten, die es bei Big Data zu beachten gilt. Eine dieser Facetten ist die Art neu generierter Daten, die zu einem immer größer werdenden Anteil unstrukturiert sind. Der Nachteil bei der Verwaltung solcher Daten ist, dass sie im Vergleich zu ihren strukturierten Verwandten deutlich schwerer zu kategorisieren und zu sortieren sind.
Im nachfolgenden Beitrag kommentiert Rob Mellor, VP und GM EMEA bei WhereScape**, den Aspekt "Integritätskontrolle bei immer größeren, vermehrt unstrukturierten Datensätzen“. (1) Nach Ansicht des Experten stellt insbesondere die Datenintegrität (1) eine komplexe Herausforderung dar, vor allem unter dem Aspekt der Datensicherheit. Denn nicht nur Volumen, sondern auch ständig neu generierte Daten, in denen Potenzial liegt, lassen sich mit Big-Data-Analytics-Lösungen nutzen. Auf was man hierbei achten sollte und wie mit Hilfe von Automatisierung des Data-Warehouses die sprichwörtliche Nadel im Heuhaufen gefunden werden kann, soll hier näher diskutiert werden.
Mangelnde Datenintegrität verfälscht Big-Data-Analysen
"Die Suche nach Wert innerhalb der Daten ist für viele IT-Verantwortlichen, trotz der Nutzung entsprechender Lösungen, wie die sprichwörtliche Suche nach der Nadel im Heuhaufen. Doch nicht nur das große Datenvolumen stellt bei dieser Suche nach wertvollen Informationen ein enormes Problem dar. Denn je mehr Informationen man hat, desto größer ist die Wahrscheinlichkeit, dass einige dieser Informationen falsch, doppelt, veraltet oder anderweitig fehlerhaft sind. Diese mangelhafte Integrität gespeicherter Daten stellt für Unternehmen natürlich eine große Herausforderung dar. Denn sind Daten verfälscht, können die aus ihnen abgeleiteten Erkenntnisse auch nicht richtig sein.
Sieht man sich die Probleme vieler Unternehmen mit ihren Ansätzen zur Datenanalyse in der Praxis an, so erkennt man, dass diese Lösungen alleine nicht ausreichen, um Datenintegrität bei großen Datensammlungen zu gewährleisten. Neue Technologien wie KI und Maschinelles Lernen können zwar helfen, auch sehr große Datensätze besser zu verstehen, doch auch ihre Ergebnisse können nur so gut sein, wie die zugrunde liegenden Daten.
Damit die Gewinnung von Erkenntnissen im Rahmen einer Big-Data-Strategie also effektiv ist, egal ob mit traditionellen Mitteln oder neueren Mitteln wie KI, muss ein gewisses Maß an Ordnung herrschen. Daten müssen also von fehlerhaften, doppelten oder alten Versionen befreit werden, bevor sie für die Analyse genutzt werden können. Nur so ist die Analyse effektiv und lässt sich zukünftig höher skalieren.
Konfigurationsfehler produzieren einen Strom fehlerhafter Daten
Fehler zu finden und zu beseitigen ist somit eine wertvolle Fähigkeit. Dies gilt generell für alle Fehler, insbesondere jedoch für grundlegende Konfigurationsfehler von Datenquellen. Bleiben diese Fehler unentdeckt, so produzieren diese Quellen einen andauernden Strom schlechter Daten – und schlussendlich natürlich auch eine uneffektive Analyse und fehlerhafte Ableitungen. Der Wert solcher Big-Data-Analysen ist natürlich gering.
Dieses Problem wird noch verschärft, wenn Daten aus mehreren verschiedenen Quellen und Systemen aufgenommen werden, von denen jede die Daten unterschiedlich verarbeitet haben kann. Die schiere Komplexität einer solchen Big-Data-Architektur kann das Aufspüren von Fehlern fast unmöglich machen. Man sucht dann nicht mehr nach einer Nadel im Heuhaufen, sondern eine Nadel in einem Stall voller Heuhaufen.
DSGVO fordert höhere Datenintegrität von Unternehmen
Inzwischen ist die Herausforderung Datenintegrität zu schaffen nicht mehr nur auf die IT-Abteilung beschränkt. Seitdem die DSGVO in Kraft ist, müssen Unternehmen Wege finden, ihre personenbezogenen Daten im Rahmen der Gesetzgebung zu verwalten – unabhängig davon, wie komplex ihre Infrastruktur sein mag, oder wie schwierig es sein kann, unstrukturierte Daten zu verwalten. Darüber hinaus müssen Unternehmen in der Lage sein, Informationen über eine Person zu löschen, zu sammeln und sogar an Behörden weiterzugeben.
Die Automatisierung des Data-Warehouse schafft Datenintegrität
Also, was ist die Lösung? Eine der besten Lösungen für die Verwaltung des Monsters „Big Data“ und eine, die die Möglichkeit bietet, Datenintegrität zu schaffen, ist die komplette Automatisierung des Data-Warehouse. Automatisiert man dieses, schafft man einen klaren Weg, der zeigt, woher die Daten stammen und wie sie im Lauf der Zeit verwendet wurden.
Darüber hinaus sind automatisierte Prozesse wesentlich einfacher zu verwalten und damit auch zuverlässiger. Um ihre Datenaufnahme und -verarbeitung zu automatisieren, nutzen Unternehmen eine moderne Automatisierungssoftware. Moderne Lösungen bieten über die effektive Automatisierung auch Funktionen, die die Abstammung von Daten bis ins kleinste Detail darstellen können. Sie können Datenquellen beispielsweise sogar nachträglich katalogisieren. Auch die Datenextraktion zur Einhaltung von Anforderungen im Rahmen der DSGVO ist mit solchen Lösungen einfach möglich.
Mit den richtigen Tools, wie der Automatisierung des Data-Warehouse, wird die Datenspeicherung im Rahmen einer Big-Data-Strategie wesentlich einfacher – und schafft gleichzeitig Datenintegrität. So können Datenprozesse einfach zurückverfolgt werden, inklusive wann und wo die Daten genutzt wurden. Big Data kann so mit all seinen komplexen Facetten gelingen und Erkenntnisse liefern, auf die sich Unternehmen auch komplett verlassen können."
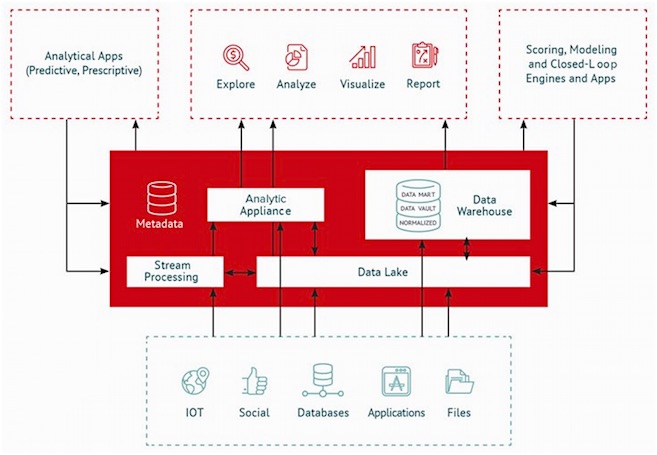
Abb. 1: „Integrating Big Data into the Enterprise", Übersicht (**Bildquelle: WhereScape Big Data Integration).
(1) Was ist Datenintegrität? Die Datenintegrität umfasst Maßnahmen, damit geschützte Daten während der Verarbeitung oder Übertragung nicht durch unautorisierte Personen entfernt oder verändert werden können. Sie stellt die Konsistenz, die Richtigkeit und Vertrauenswürdigkeit der Daten während deren gesamten Lebensdauer sicher und sorgt dafür, dass die relevanten Daten eines Datenstroms rekonstruierbar sind. Die Datenintegrität bildet in Kombination mit dem Datenschutz und der Datensicherung die Eckpfeiler einer verlässlichen Informationsverarbeitung.
Querverweis zum Thema:
{kind=link}