Starnberg, 19. April 2021 - Der Schnittpunkt zwischen künstlicher Intelligenz und modernen Anwendungen sind die Daten; Engpässe liegen potentiell auf der Speicherebene...
Zum Hintergrund: IoT oder Big Data Analytics werden die Datenkapazitäten weiter und vor allem auch immer schneller vergrößern. Für Unternehmen sind diese Daten aber nur dann wertvoll, wenn sie in einen sinnvollen betrieblichen Zusammenhang gestellt werden können. Hier setzt KI an, denn alle wesentlichen Elemente dieses Ökosystems wie auch die Bereiche Robotik, Sensorik, Speicherverwaltung, Netzwerke etc. müssen künftig dadurch unterstützt werden. Folgt man diversen Studien, soll dieser Trend zeitnah bei vielen Unternehmen bereits über deren Wettbewerbsfähigkeit entscheiden. Jedenfalls werden neue Technologien ihr volles Potenzial erst dann entwickeln können, wenn die Unternehmen in der Lage sind, das Internet der Dinge mit den Möglichkeiten der Künstlichen Intelligenz wertschöpfend zu verknüpfen (1)
1) Anforderungen an "KI-ready" Storage
Latenzen und der Durchsatz der Speichersysteme wirken sich direkt auf die Leistung eines KI-Gesamtsystems aus (balanced system). Der zentrale Datenengpass liegt dabei meist auf der Speicherebene und der Fähigkeit, höchsten Durchsatz (IOPS, GB/s) bei möglichst niedrigen Latenzzeiten zu liefern. Moderne Implementierungen von z.B. maschinellem Lernen sind stark auf GPU-basierte parallele Berechnungen angewiesen und diese wiederum benötigen einen extrem schnelle Speicher (DRAM, Persistent Memory, Flash). Storage-Systeme, die handelsübliche SSDs mit seriellen Schnittstellen (SATA, SAS) verwenden, stoßen dabei schnell an Leistungsgrenzen.
NVMe und NVMeoF sind wichtige Technologien & Protokolle für den schnellen Datenspeicher. Zu beachten ist Anwendungsseitig auch, dass bei Deep Learning-/Machine Learning zwar der Data Ingest ein relativ einfaches Streaming von sequentiellen Schreibvorgängen impliziert, weitere Prozesse jedoch aus vielen kleinen zufälligen Lese-Operationen bestehen können. KI zur Mustererkennung beim Datenzugriff selbst, um die Daten schon in den Cache zu holen, bevor sie benötigt werden, ist hier hilfreich. Für die Archivierung der „kalten“ Daten sollten die Daten automatisiert auf Basis definierter Richtlinien weiter in den Objekt-Storage-Bereich (on-prem/Cloud) verschoben werden können.
2) GPUs, CPUs und Storage
Um ein ausgewogenes Systemdesign zu erreichen, müssen den GPUs genügend Daten zur Verfügung stehen, das ist nicht anders als bei jeder konventionellen Server-Applikationsumgebung (Stichwort: Balanced System); Verzögerungen führen zu unausgelasteten GPUs und der gesamte Prozess wird verlangsamt. Die Bandbreite der Datenübermittlung ist hoch und ein einzelner Knoten kann Daten mit 3 GB/s und mehr verarbeiten, insbesondere wenn hochauflösender Bilder - also große Datensätze - entstehen. Bei kleineren Datensätzen ist das Problem nicht so groß, weil das neuronale Netzwerk innerhalb jeder Trainingseinheit auf die gleichen Daten zugreift. Diese können dann lokal auf Flash oder RAM zwischengespeichert werden.
Bei Deep Learning (DL) bedeutet ein langsamer Speicher eine langsamere maschinelle Lernleistung, denn das Deep Neural Network stellt ein Abbild eines massiv parallelen vernetzten Modells dar, bei dem bis zu Milliarden von Neuronen lose miteinander verbunden sein können, um ein einziges Problem zu lösen. GPUs wiederum sind massiv parallele Prozessoren, bei denen jeder einzelne aus Tausenden von lose gekoppelten Rechenkernen besteht, um eine entsprechend höhere Leistung als Standard CPUs zu erzielen.
3) Flash Storage Limits
Zufällige Leseleistung bei geringer Warteschlangen-Tiefe ist bislang ein Bereich, bei dem NAND Flash SSDs sowie Flash JBODs allein (ohne Caching) nicht optimal liefern. Persistent Memory liefert nach den Specs bis zu 10-fache Leistungswerte Flash-basierter SSDs bei (random) read queue depth von 1-4 (3D-XPoint-Technologie wie Intel Optane). Die Leistung von Speichersystemen wird damit erhöht und dies wiederum hilft beim Design von parallelen high-performance KI-Infrastrukturen.
Hohe Leistungswerte bieten ebenfalls aktuelle NVDIMMS Speicher, die Persistenz mit DRAM-Performance kombinieren (siehe Abb. unten). NVMeoF und RDMA über InfiniBand oder 100 GBE für skalierbare Speicherpools sind Hardware- und Protokollseitig geeignete Protokolle für Low-latency - high Performance I/O - Architekturen im Verbund mit NAND (Kostenaspekte) und Persistent Memory (Leistungswerte / Haltbarkeit).
Es ist aus Sicht von KI-Anwendungen notwendig, dass für anspruchsvolle Lastprofile eine aktuelle, sehr leistungsfähige Generation von Speichersystemen eingesetzt wird, um GPU-Systemen die entsprechend hohe "Ingest"-Bandbreite für zufällige (random) Zugriffsmuster von kleinen bis großen Files zu liefern.
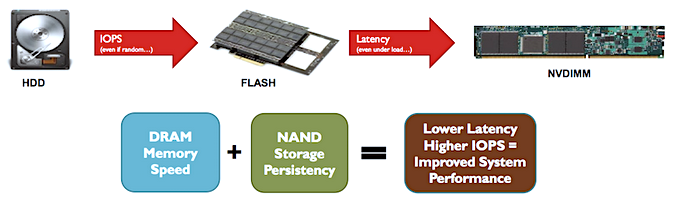
Abb. 1: NVDIMM-N, Übersicht (Bildquelle: In-Memory-Computing Summit, US)
4) IoT oder Data Storage im Edge
- Weitere Storage-Anforderungen betreffen das künftig immer stärkere Datenwachstum im Edge, das es zu adressieren gilt. Daten können hier von einem bestimmten Sensor oder einer Gruppe von Geräten übertragen werden, sie können zudem ereignisgesteuert sein, d.h. weniger vorhersehbare Muster bei der Datenübertragung sind zu erwarten. Auch das Volumen und die I/O-Muster können zufällig (random) sein. Edge-Storage-Dienste können sich überall befinden, im Rechenzentrum, in der Cloud oder in der Nähe der Datenquelle.
Ein Fazit
Die intelligente Verwaltung und Speicherung von Daten sind zentrale Bausteine im Zuge der Digitalisierung. Aufgrund des raschen Datenwachstums und neuer Applikationsfelder im Edge ist eine dafür optimierte Speicher- und Daten Management Strategie (Edge-to-Core-to-Cloud) unabdingbar für den künftigen wirtschaftlichen Erfolg. Traditionelle Storage Modelle auf Basis von SAN und NAS sind dafür nicht konzipiert. Hier kommen dann bevorzugt Technologieoptionen wie fast-object & scale-out Filesysteme sowie schnelle Speichermedien (DRAM, SCM, NAND Flash) zum Einsatz.
(1) Quelle:
Sizing the prize What’s the real value of AI for your business and how can you capitalise? PWC 2017,170905-115740-GK-OS > http://www.pwc.com/AI
Unser Beitrag > McKinsey Studie zu Künstlicher Intelligenz: Größeres Potenzial als die Dampfmaschine