Starnberg, 09. April 2021 - Auf welche Randbedingungen und Funktionen bei der Evaluierung von Objektspeicherlösungen genauer geachtet werden sollte; eine Übersicht...
Um was es hier geht: In diesem Blogbeitrag wird auf einige kritische Beschaffungsmerkmale hingewiesen, die Anwender bei der Evaluierung von Objektspeicherlösungen beachten sollten. Der Begriff Objektspeicher bezieht sich auf Systeme, die Daten als "Objekte" speichern und Benutzern diese über RESTful HTTP APIs zur Verfügung stellen, wie Amazon Simple Storage Service (S3) und OpenStack SWIFT. Katalysatoren für den Einsatz von Objekt-Speichersystemen sind natürlich das rasche Datenwachstum aber auch neue Anwendungen, was zum Teil verstärkte Investitionen in hybride Cloud Implementierungen nach sich zieht, um Flexibilität, Kostenvorteile über „pay as you use“ sowie die skalierbare Leistung von Cloud Services zu nutzen. Das Interesse von Entwicklern an neuen Anwendungen im Zuge der Digitalisierung nimmt jedenfalls zu. Diese Teams sind, auch getrieben durch das Business, auf der Suche nach agilen IT-Infrastrukturlösungen, die sich von on-premise auf die Public Cloud über hybride-/Multi Cloud Deployments skalierbar ausdehnen lassen. Objekt Storage ist sowohl on-premise als auch in der Cloud ein Lösungsansatz, aber was gilt es aus technischer Sicht bei der Beschaffung zu beachten?
1. Die Unterstützung von Filesystem-Protokollen im Zusammenhang mit Objektspeicher-Lösungen haben den Vorteil, bestehende Anwendungen mit SMB, CIFS, NFS ohne große Modifikationen betreiben zu können. Verteilte (Cluster-) Scale-out Filesysteme als integrierter Teil des objektbasierten Systems sind in der Lage, auch mit nicht-nativen Anwendung zu arbeiten und erweitern das Einsatzspektrum erheblich. Anmerkung: Verteilte Dateisystem-Speichersysteme verwendet ein paralleles Filesystem, um mehrere Speicherknoten als Cluster zu betreiben, die über einen gemeinsamen Namensraum zum Speicherpool abgebildet werden; dies erlaubt Datenzugriffe für mehrere Hosts parallel mit hoher Bandbreite. Falls der File-Zugriff über Gateways implementiert wird - im Vergleich zu einem nativen Protokoll ohne Single-Point-of-Failure - stellt das einen potentiellen Ausfallpunkt dar und ist zudem mit Mehraufwendungen, sprich Kosten verbunden (Capex, Opex). Hybride Cloud-Speicherfunktionen fungieren als Brücke zwischen firmeninternen (on-premise) und öffentlichen Cloud-Umgebungen. Hier bestehen trotz S3 Unterschiede zwischen den verschiedenen Anbieterlösungen.
2. Hier einige Unterscheidungsmerkmale in Bezug auf die Leistungsfähigkeit von Enterprise Object Storage Architekturen:
- Robuste Metadaten-Implementierung - eine der zentralen Komponenten, die in einem verteilten System entsprechend leistungsfähig, hochverfügbar und sicher skalieren muss.
- Hohe horizontale Skalierung (Hunderte PBs und Knoten, Milliarden Objekte, Proxy, Balancer usw.)
- Preisgünstiger Speicher auf Basis x86 Infrastrukturen mit hochkapazitativen Laufwerken
- Synchrone und asynchrone Replikation über separates VLAN (und IPv6 Unterstützung); Speicherung über Geo-Infrastrukturen bis auf Namespace-Ebene
- Selbst-optimierendes System mit Encryption, Deduplizierung und Kompression auf Namespace-Ebene
- Integrierte HSM Funktionalität (NFS, S3, LTFS (?!) mit Tape
- Verfügbarkeit als virtuelle Systemumgebung.
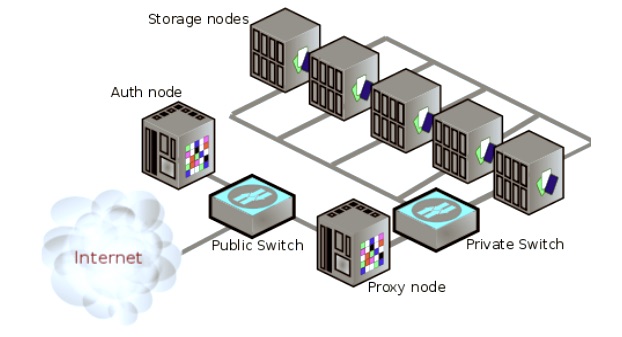
Abb. 1: OpenStack Object Storage (Bildquelle: SNIA Tutorial, Object Storage Key Role in Future Data)
3. Weitere Punkte, die aus Praxissicht bei der Implementierung von Object Storage beachtet werden sollten:
- Objektspeicher verlangt nach möglichst erfahrenen Web-Spezialisten für DNS, HTTP, Squid, Loadbalancer, Cache-Engines, Webserver und HTTP-Transaktionen, die aber auch speicher-spezifischen Themen verstehen
- SWIFT basiert auf der jeweiligen OpenStack Implementierung –manche Java Libraries z.B. benötigen hierfür spezielle (SWIFT-) Implementierungen
- Komplexe Multi-Layer-Architekturen machen eine potentielle Fehleranalyse komplexer
- Sicherheitsaspekte sind extrem wichtig und unabdingbar, also Themen wie Intrusion-Detection, Zertifikatsmanagemente usw.
- Art der S3-Implementierung: AmazonS3 ist kein komplett offengelegtes Format und jeder Anbieter kann es im Prinzip implementieren. Zu beachten ist, dass manche Anwendungen wie Hadoop nur mit spezifischen Erweiterungen robust und fehlerfrei arbeiten
- HTTP Merkmale: URL-Hiding, HTTP Traversal (aka Forceful Browsing / Sicherheitslücken) sind Funktionen, die manche Lösungen nur teilweise unterstützen.
- Ein Archivspeicher sollte mit dem jeweiligen Objektstorage vollständig kompatibel sein –teilweise sind Zertifizierungen erforderlich.
- Unterstützung für Cloud-native Umgebungen, Flash-Optimierung
- AWS S3-Compliance-Vorgaben, Ransomware Schutz über die Unveränderlichbarkeit von Daten usw..
Ein Fazit: IT-Teams und Verantwortliche, die hoch skalierbare, nach Möglichkeit selbstheilende und kostenoptimierte Speicherplattformen auch für große Mengen an unstrukturierten Daten benötigen, kommen an Objekt-Speicherplattformen nicht vorbei. Um die geeigneten Produkte für ihre Anwendungsfälle zu identifizieren, ist es allerdings unabdingbar, seine Anforderungen an die Systeme vorher genau zu kennen. Dies betrifft insbesondere die Anwendungsseite. Durch die Kombination von Objektspeicher mit scale-out Filesystemen entstehen entsprechend flexible Einsatzszenarien für unterschiedlichste Anwendungsbereiche.
Diesen Beitrag als Podcast hören > Link auf unsere Podcastseite bei Apple iTunes™
Querverweise:
Blopost > Wann ist der Einsatz von Object Storage in meinem Betrieb empfehlenswert?
Gartner Distributed File Systems and Object Storage > https://www.gartner.com/reviews/market/distributed-file-systems-and-object-storage
Aktuelle Anbieterlösungen (zufällige Reihenfolge; kein Anspruch auf Vollständigkeit):
- Hitachi Content Platform Anywhere > https://www.hitachivantara.com/en-us/products/storage/object-storage.html
- IBM COS > https://www.ibm.com/de-de/products/cloud-object-storage
- NetApp StorageGRID > https://www.netapp.com/de/data-storage/storagegrid/
- Cloudian HyperStor > https://cloudian.com/de/
- Scality Ring > https://www.scality.com/
- Quantum ActiceScale > https://www.quantum.com/object-storage
- Red Hat Ceph Storage > https://www.redhat.com/en/technologies/storage/ceph
Weitere File-/Object Anbieterlösungen finden sich bei Dell EMC, Suse Enterprise Storage, HPE, Fujitsu, Qumulo, MINIO, Pure Storage, WekaFS, Cohesity, Nutanix u.a.