Starnberg, 04. Mai 2022 - Vorteile von verteilen Hochleistungs-Filesystemen in Kombination mit skalierbarem S3-Objektspeicher bei datenintensiven Applikationen im Blogpost...
Um was es in diesem Beitrag geht: Der jeweils beste Weg, um Daten in ML-Modelle zu laden, hängt dabei davon ab, ob vor Ort oder in der Cloud gearbeitet werden soll. Weitere Randbedingungen betreffen die Größe der Datensätze, Verarbeitungs- und Durchsatzraten, vorhandene Speichertechnologien sowie betriebsspezifische Sicherheits- und Datenschutz-Anforderungen. Weiter erfordert die Speicherung und Verarbeitung einen möglichst einheitlichen Zugang zu diesen Datensätzen. Daraus leiten sich die IT-System- und Infrastrukturanforderungen ab.
Besonders komplexe KI-Anwendungen mit teils massiven Datensätzen verlangen nach skalierbar hoher Kapazität und I/O-Leistung, dies bei geringer Latenz und zu vertretbaren Kosten. Direct Attached Storage (DAS) sowie klassischer SAN-/NAS-Speicher skalieren bei anspruchsvollen Workloads in Bezug auf die kritischen Parameter wie I/O-Leistung, Latenz, lineare Erweiterbarkeit, OPEX und CAPEX nicht, oder nur ungenügend.
Welche Speicherumgebung für Datenanalyse- und KI-Anwendungsfälle?
Aus Storage-Sicht stehen uns grundsätzlich File-, Objekt- und Blockspeichersysteme auf Basis HDDs und Flash zur Verfügung. Jeder Ansatz verfügt über eigene Charakteristika mit Vor- und Nachteilen. Für KI und maschinelles Lernen wird generell ein System benötigt, das verschiedene Arten von Workloads mit sowohl kleinen als auch sehr großen Dateien skalierbar verarbeiten kann. Die Herausforderung: Nicht alle Speicherarten sind gleich gut für große Dateien geeignet und nicht alle können gleichzeitig mit sehr kleinen Dateien umgehen.
Die objektbasierte Speicherung ist besonders für unstrukturierte- und langsam auch semistrukturierte Daten im Rahmen von Cloud-Bereitstellungsmodellen konzipiert, sowohl on-premise oder in Kombination mit Public Cloud Umgebungen. In objektbasierten Architekturen werden die Daten immer in einer flachen Umgebung als unabhängige Einheiten gespeichert. Es gibt keine Speicherhierarchie noch andere Arten von Strukturen wie bei Filesystemen. Objektspeicher erreichen damit eine horizontale, quasi unbegrenzte Skalierung. Benutzer können die Objekte mit Metadaten anreichern, so dass sie sich für weitere Zwecke wie Datenanalysen verwenden lassen. Daten in diesen Strukturen - als Objekte bezeichnet - werden über RESTful HTTP-APIs wie S3 zur Verfügung gestellt. Ein Grund, warum KI- und ML-Systeme Objektspeicher verwenden, liegt neben den Speicherkosten auch in dessen relativ unkomplizierter Erweiterbarkeit und der Fähigkeit, die Daten hochverfügbar und sicher zu halten.
Bei klassischen File Storage (NAS) Systemen bedeutet ein Ausbau des verfügbaren Speichers in der Regel eine vertikale Skalierung durch Hinzufügen weiterer Systeme innerhalb der Infrastruktur. NAS eignet sich deshalb besonders für Anwendungsfälle, in denen keine Massendaten verarbeitet werden, die komplexe Organisationsstrukturen und höchste Leistung erfordern.
Verteilte, hochparallel arbeitende (scale-out) Filesysteme auf Basis einer globalen Namenspace-Architektur in Kombination mit hochkapazitativen Festplatten- und schnellem Flashspeicher kombinieren die Einfachheit von NAS mit besserer I/O- und Durchsatzleistung von DAS, ergänzt um S3 Objektspeicher und je nach Bedarf Tape Storage als Archiv mit einer annähernd unbegrenzten Ausbaufähigkeit in der Cloud. All-Flash unterstützt vor allem den schnellen Zugriff auf bestimmte Datenbereiche innerhalb der Produktions-Clusterumgebung. Dies führt direkt zu einer Steigerung der Infrastrukturleistung und beschleunigt Datenverarbeitungsprozesse - insbesondere für kritische Business-Analyse-Anwendungen, wie sie im Sinne eines beschleunigten Return on Value (ROV) im Rahmen von KI-Projekten erforderlich sind.
Beispiel: Entwicklung im Bereich Autonomes Fahren
Deep-Learning (DL-) Systeme stellen schon durch die Geschwindigkeit der Datenerfassung und -verarbeitung eine Belastung für jede Speicher- und Berechnungsinfrastruktur dar. Bei einer Flotte von Trainingsfahrzeugen erzeugt die tägliche Datenerfassung extrem viele Daten, die in ein vorhandenes Data Lake eingespeist werden müssen. Ein weiterer Aspekt betrifft die Auslastung der GPU-Server: Standard NAS-Appliances mit Flash skalieren zwar in der Regel gut für die erste Modellentwicklung, sind aber nicht für ein fertiges KI-Produktionssystem mit hunderten von GPU-Servern sowie PBs an täglich neu hinzukommenden Daten designed. Datensätze, die zum Trainieren der KI-Modelle verwendet werden können aus sehr vielen kleinen Bilddateien gemischt mit großen Datensätzen gemischt bestehen. Diese werden mit einer Bandbreite von 10 GByte/sec. und mehr gelesen, um die GPU-Server zu sättigen. Ein Standard All-Flash NAS Filer kann die GPU-Server aber nicht immer ausreichend mit Daten versorgen. Dazu kommen höhere Latenzzeiten durch Performance-Einschränkungen bei NFS. Eine weitere Randbedingung betrifft die Frage, ob Flash aus Kostengründen auch für den Datenkatalog benötigt wird. Eine Software-kontrollierte Speicher- und Filesystem-Architektur mit niedrigeren Kosten auf Basis von schnellen Festplatten erlaubt flexiblere Deployment-Modelle für die zugrunde liegende Hardwareinfrastruktur.
In dem Umfeld positioniert sich S3 Objektspeicher mit Flash zunehmend gegenüber NAS- oder DAS-basierten Primärspeicherlösungen. Ergänzt wird dieser Ansatz mit hochparallelen Filesystem-Architekturen, deren Ziel es ist, die Daten über die softwaredefinierte Speicherverwaltung und -Infrastruktur auf Basis Flash und HDDs zu verteilen, um einen massiv parallelen Datenzugriff zu erreichen. Niedrige Latenzzeiten bei hoher Bandbreite sowohl für Daten- als auch für Metadaten-Operationen sind dann möglich. Der angeschlossene Objektspeicher verfügt über die geforderte hohe Datenverfügbarkeit und -integrität und skaliert entsprechend zu niedrigeren Speichergesamtkosten. Gegenüber Standard NFS-basierten All-Flash-Systemen lässt sich in dieser genannten Kombination neben einer höheren Ausfallsicherheit-/Verfügbarkeit (Beispiel: erasure coding) die CPU- und GPU-Auslastung eines KI-Systems um Faktoren verbessern.
Fazit: KI-Anwendungen mit massiven Datensätzen verlangen nach skalierbar hoher Kapazität und I/O-Leistung, dies bei geringer Latenz und zu vertretbaren Kosten. Direct Attached Storage (DAS) sowie klassischer SAN-/NAS-Speicher skalieren bei diesen Workloads in Bezug auf kritische Parameter wie I/O-Leistung, Latenz, lineare Erweiterbarkeit, OPEX und CAPEX nicht. Speichertechnologien und Protokolle wie NVMe(oF) im Verbund mit jetzt QLC-NAND, DRAM-Caching, Storage Class Memory und massiv paralleler Filesystem- und Speichersoftware, insbesondere für steigende Bandbreitenanforderungen mit zufälligen Zugriffsmustern von kleinen bis sehr großen Files, sind die Antwort auf stetig steigende Anforderungen in diesem wachsenden Applikationsumfeld.
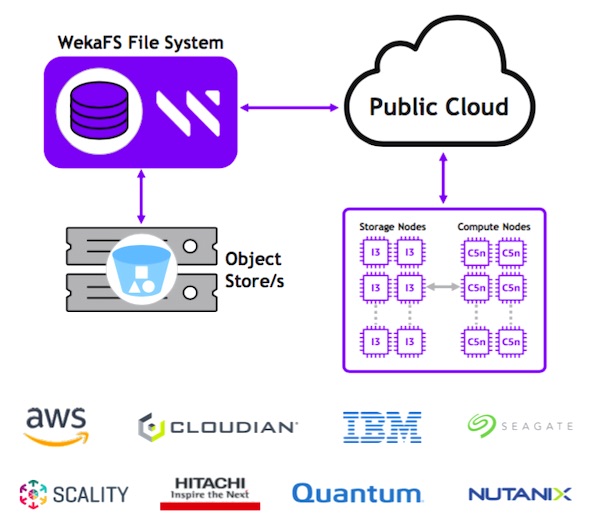
Abb. Unified Namespace Architecture, hier am Beispiel von WEKA IO (Bildquelle: WEKA). Ergänzung zur Abbildung: WEKA IO Snap-to-Object ermöglicht die Auslagerung von Daten in die Cloud für Backups, Archivierung oder Datenmigration.
Weitere Anbieter von verteilten Scale-Out File Storage Systemen sind Dell, NetApp, Qumulo, VAST Data, IBM, Quantum, Red Hat, Nutanix, Hitachi Vantara, Huawei, Scality, Panasas (HPC), Pure Storage... (kein Anspruch auf Vollständigkeit).
Kommentar zu WEKA: WekaFS stellt ein POSIX-konformes, paralleles Scale-out Filesystem dar, das in der Lage ist die Beschränkungen klassischer Dateisysteme (FS's die lokalen Speicher, NFS oder Blockspeicher nutzen) zu umgehen. Damit ist es für datenintensive KI- und High-Performance-Computing-Workloads geeignet. WekaFS integriert NVMe-basierten Flash-Speicher auf der I/O-Leistungsebene mit GPU-Servern, Objektspeicher und Interconnect-Fabrics mit niedriger Latenz innerhalb einer NVMe-over-Fabrics-Architektur. Die Leistung skaliert linear, wenn weitere Server zum Speichercluster hinzugefügt werden.
Bei herkömmlichen Speichersystemen liegt die Dateiverwaltungssoftware oberhalb des Blockspeichers. MatrixFS von WEKA IO macht diese Blockvolumenebene zur Verwaltung der zugrunde liegenden Speicherressourcen überflüssig. Der vertikal integrierte Architekturaufbau beseitigt die Einschränkungen klassischer gemeinsam nutzbarer Speicherlösungen (shared SAN/NAS-Storage) und bietet Kapazitätseffizienz (z. B. Platzeinsparung) sowie Leistungseffizienz (Produktivität). Ein wichtiger Vorteil ist, dass MatrixFS wenig genutzte Daten auf Dateibasis verwalten kann, was herkömmliche Systeme über volumenbasiertes Thin Provisioning erreichen (Speichereffizienz).
Querverweis:
Link auf Podcast-Beiträge zu dem Themenkomplex > https://podcasts.apple.com/de/podcast/storage-consortium/id81294878
Weitere Informationen zum Thema "Verteile Filesysteme und Objektspeicher" mit Anbieterinformationen finden sich auch bei Gartner Peer Insights(TM) unter diesem Link > https://www.gartner.com/reviews/market/distributed-file-systems-and-object-storage