Starnberg, 25. Juni 2021 - Vom klassischen Speichermanagement zur agilen Datenverwaltung in hybriden Clouds; Data Management als strategischer Differenzierungsfaktor...
Um was es hier geht: Bis 2025 sollen Prognosen zufolge weltweit rund 163 Zettabyte an Daten p.a. erzeugt werden (Quelle: IDC). Diese Volumina umfassen u.a. immer mehr Daten von mobilen Compute-Devices, aus dem Internet über IoT-Sensordaten sowie maschinell generierte Datenströme von prozessbezogenen Quellen. Die Möglichkeit der aktiven Nutzung dieser Daten im Sinne eines Mehrwerts für die Unternehmen wird den künftigen wirtschaftlichen Erfolg entscheidend mitbestimmen. Welche Rolle eine zukunftsfähige software-definierte Datenstrategie in diesem Zusammenhang spielt, und was diese von der klassischen hardware-zentrierten Speicherverwaltung unterscheidet, soll in im Folgenden näher beleuchtet werden.
Unternehmensweit eingesetzte universelle Datenspeichersysteme sind für die hochverfügbare Speicherung und Archivierung großer Informationsmengen geschaffen. Die damit verbundenen Storage-Management - Funktionen sind im Gegensatz zu kleineren lokalen Speicherlösungen darauf ausgelegt Workloads, d.h. I/O-Profile von vielen unterschiedlichen Benutzern - hauptsächlich über File- und Blockzugriffe - zu verwalten. Sie werden als virtualisierte, (logisch) zentralisierten Infrastrukturen, wie Network-Attached-Storage -(NAS), Storage Area Network (iSCSI, FC SAN-) Arrays, aber auch direkt angeschlossenen Speicher für spezifische Anwendungs-Workloads (Direct Attached Storage, DAS) mit einer direkten LUN-zu-App-Beziehung implementiert. In diesem Zusammenhang beginnt sich auch Computational Storage stärker zu entwickeln. Der Begriff definiert Architekturen, die mit dem Speicher gekoppelte, rechnergestützte Storage-Funktionen bereitstellen, um die Server-Verarbeitung zu entlasten und/oder Datenbewegung über Netzwerke zu minimieren. Ein Teil der Datenverarbeitung erfolgt nun direkt auf der Speicherebene, anstatt die Daten in den Hauptspeicher zur Verarbeitung durch die Host-CPU zu verschieben. Dieser Ansatz ermöglichen Verbesserungen bei der Anwendungsleistung mittels Integration von Rechenressourcen außerhalb der traditionellen Rechen- und Speicherarchitektur entweder direkt mit dem Speicher oder zwischen dem Host und dem Speicher.
Zentrale Funktionen leistungsfähiger Speicherverwaltungssoftware-Lösungen umfassen die (remote-)Überwachung, Verwaltung und Fehlerbehebung zu allen wesentlichen Komponenten des Unternehmensspeicher-Systems und beinhalten zudem Parameter für die Komprimierung, Deduplizierung, Auslastung-, Speicherbereitstellungs- und Performanceoptimierung. Neben der reinen Überwachung aller hardwarenahen Systemelemente lässt sich damit auch die Einhaltung von Vorschriften in Bezug auf Datenaufbewahrung (WORM-Feature) und Datenschutzstandards vereinfachen. Eine plattform-übergreifende Speicherverwaltung im Unternehmen ist für die Skalierbarkeit der Speicherarchitektur insgesamt von Bedeutung, weil vorhandene Kapazitäten je nach Geschäftsanforderungen relativ unkompliziert und schnell erweitert oder migriert werden können. Das Storage Management adressiert dabei die Verlagerung von Speicherkapazitäten bis in die Cloud, das Hinzufügen von weiterer Hardware wie Controller, Festplatten und SSDs sowie virtualisierter (disk-)Ressourcen auf Grund von Erweiterungen mit Hypervisor-Systemen.
Computational Storage ist für Hochleistungs-Workloads von modernen Datenbanken und Big Data Analytics geeignet. Typischerweise verfügen diese Systeme auf Grund des Einsatzzweckes über eine für die Systemumgebung optimierte Speicher- und Filesystem-Verwaltung, während eine kommerziell breit verfügbare Enterprise-Speicherverwaltungsplattform auch rein als Software zusammen mit JBODs (just-a-bunch-disks oder SSDs) implementiert werden kann.
Die einheitliche Verwaltung von Unternehmensspeicher-Ressourcen vereinfacht Backup-Restore- und Disaster Recovery- Prozesse erheblich. Mit der geeigneten Speicherverwaltung lassen sich Ressourcen gezielt zuweisen, um Ausfälle zu vermeiden und die Leistung zu verbessern. Zentrale Datenspeicher, bislang typischerweise skalierbare (FC-)Hochleistungs-Arrays in Kombination mit Schnittstellen und Tools zum Datenschutz sind zur umfassenden Verwaltung von Unternehmensdaten mit Schutz- und Freigabeprotokollen sowie einem einheitlichen Ansatz für den Zugriff auf und die Sicherung von Geschäftsinformationen versehen, aber doch herstellerspezifisch, weil hardware-nah, implementiert. Dieser Ansatz hat sich für definierte Anwendungsfälle (Block-, File) zwar bewährt, ist jedoch auf Grund der zunehmenden Menge an unstrukturierten Daten und rasch wachsender neuer Anwendungs-Workloads (Millionen Objects, Hundertausende Container) nicht hinreichend skalierbar und stößt wirtschaftlich dann an Grenzen.
Cold Data und Cloud Storage Management
Auf immer mehr Daten wird immer weniger zugegriffen (cold data); kostenseitig stellt dies nicht nur im eigenen Rechenzentrum, sondern auch für Cloud-Anbieter auf Grund des Wachstums zunehmend ein Problem dar. Es ist deshalb sinnvoll, die Konsolidierung von Flash, hoch-kapazitativen Festplatten und Bänder zu einer mehrstufigen, unter Einbeziehung von Cloud-Speicherlösungen, logisch einheitlich zu verwaltenden Architektur, in Betracht zu ziehen. Im Zusammenhang mit systemnahen Archiven wird dieser Ansatz oft unterschätzt. Ein Beispiel: Standard Office-Anwendungen erzeugen die Masse aller Geschäftsdaten und diese Daten altern zügig, was zu immer mehr online-Speicherkapazitäten bei nur geringer Aktivität (Zugriffshäufigkeit) führt. Eine Speicherung der kalten Daten auf Band oder in der Public Cloud macht dann Sinn, um zusammen mit HDDs und Flash eine kostenoptimierte, mehrstufige und hybride Speicherverwaltungslösung aufzubauen (automatisiertes Data Life-Cycle Management). Damit kann „die Wolke“ als weitere, nahtlos integrierte Speicherebene (Tier) etabliert werden, ohne dabei die Kontrolle über seine Daten zu verlieren.
Hier gilt es aber zu beachten, dass Langzeitdaten inzwischen häufiger als Quelle für Analysen oder sogar als primärer kostengünstiger Speicher für selten abgerufene Daten angesehen werden. Für jedes Unternehmen summieren sich dann diese Speicherkosten über den gesamten Lebenszyklus bei den Cloud-Storage-Anbietern. Diese Kosten können innerhalb kürzester Zeit steigen, indem die abzurufende Datenmenge auch nur um wenige Prozente verändert wird. Bis die Daten für die Nutzung durch den Endbenutzer vor Ort zurückgeholt werden, sind die Kosten dann oft höher als bei der Verwendung von Primärspeicher-Systemen und on-premise Lösungen (Cloud-Anbieter erheben zusätzliche Gebühren für Befehle, die gesendet werden, um Daten aus dem Langzeitarchiv abzurufen). Um so wichtiger ist es deshalb, dass eine intelligente Datenverwaltungs-Strategie auch die möglichst automatisierte Klassifizierung relevanter Daten vor der Migration in die Cloud berücksichtigt.
Von Hardware-zentrierter Speicherverwaltung zu Software-Definierten Architekturen
Um Angesichts einer beschleunigten Transformation erfolgreich zu sein, sollten zwei kritische Aspekte beachtet werden: einerseits vorhandene Ressourcen und Fähigkeiten durch Innovationen nutzen und andererseits in neue Märkte und Technologien investieren, in denen vorhandene Ressourcen bzw. Fähigkeiten direkte Wettbewerbsvorteile liefern. In Bezug auf den IT Betrieb (ops) und der Anwendungsentwicklung (dev) - Gartner hat das als „Bi-modale IT“ definiert - ergeben sich an den Storage und das Daten-Management jeweils ganz spezifische Anforderungen.
Entwickler schätzen Hyperscale-Anbieter wegen der agilen und schnellen Bereitstellung von Ressourcen. Diese Fähigkeit beruht im wesentlichen auf Software-definierten Compute- und Speicherumgebungen (SDS) um kostenoptimierte IT-Infrastrukturdienste anzubieten. SDS verwendet dazu eine verteilte Systemarchitektur, für Primär-, Sekundär- und Archivdaten. Das ist auch der Grund, weshalb sich Software-gesteuerte Infrastruktur-Implementierungen mittelfristig auch in der Breite wohl als dominierende Methode zum Aufbau von hybriden- und Multi-Cloud-Speicherinfrastrukturen durchsetzen werden. Dies geht einher mit dem allgemeinen Trend bei Unternehmen, sich weg von isolierten Infrastrukturen hin zu flexibleren, skalierbaren Cloud-unterstützen hybriden Plattformen zu bewegen. Automatisierung und DevOps-Verfahren, um schneller Cloud-native und skalierbare Anwendungen auf Basis von Containern sowie Mikroservices zu erstellen, sind dazu notwendig, aber parallel dazu ist es auch wichtig, wie bisher im Produktivbetrieb die Anforderungen nach Hochverfügbarkeit, Performance, Compliance- und Datensicherheit-/Schutz zu erfüllen.
Während wie gesehen im klassischen Anwendungsumfeld (ops) primär die Stabilität im Betrieb im Fokus steht, gilt beim Mode 2 (dev) Agilität als oberstes Prinzip, doch dass beginnt sich gerade zu ändern. Bei Projekten im Zusammenhang mit anwendungskritischen Container-Umgebungen und Microservices wird Storage nicht mehr nur als flexible Option, sondern als hochverfügbare Software Definierter Dienst für Block-, File- und Objekt gefordert. Ein Motivation für diese Entwicklung liegt natürlich auch darin, dass ein Anwender, der jetzt einen neuen Container deployed, sich nicht mehr an einen Storage Admin. wenden muss, falls er Speicherressourcen für sich beansprucht; jetzt initiiert er seinen Container über Openshift via Kubernetes und bekommt den zugehörigen Storage Container automatisch gemapped. Mit einer nicht in diese Architektur integrierten externen Speicherverwaltung ist das in der Form nicht möglich.
Kennzeichen und Vorteile einer integrativen Datenstrategie
Unternehmen, die einen integrierten Ansatz verfolgen, sind in der Lage, die Bereitstellung von Anwendungen zu beschleunigen und komplexe Infrastruktur-Silos aufzulösen. Software Definierte Infrastrukturen sind dabei für das Datenmanagement essentiell, weil sich im Kontext einer bi-modalen IT damit zwei Ziele im Auge behalten lassen: Beweglichkeit und Elastizität des Storage-Layers im laufenden Betrieb. Mehr Kapazität oder Rechenleistung bedeutet hier: Sie fügen diese Ressourcen als hoch-virtualisierte Instanzen im laufenden Betrieb hinzu. Mehr Kapazität oder keine Hardware zur Verfügung: Sie nutzen kostengünstige skalierbare Ressourcen innerhalb der Public-Cloud im laufenden Betrieb. Damit können Unternehmen jederzeit auf sich verändernde Anforderungen reagieren. Soweit jedenfalls zur Theorie, denn leider ist in der Praxis die Integration des Storage im Sinne der oben genannten übergreifenden Architektur zwischen on-premise und Cloud in vielen Unternehmen nicht gelöst. Storage und das damit verbundene Datenmanagement stellt unzweifelhaft eine der wichtigsten Komponenten von Cloud Native Computing dar, aber persistente Speichersysteme laufen in der Regel (noch) außerhalb der nativen Cloud-Umgebungen auf separaten Systemen.
Das Interesse an der Bereitstellung von Stateful-Applikationen auf (Kubernetes-)Clustern steigt auch deshalb, weil sich Anwender nicht auf ein separates Team verlassen wollen, das ihren Speicher extern verwaltet. Es ist kostengünstiger und zeitsparender, wenn dieselben IT-Mitarbeiter, die den Kubernetes-Cluster verwalten, auch alle mit diesem Cluster verbundenen Speicherressourcen verwalten. Zudem hat die Anzahl zustandsabhängiger Anwendungen inzwischen zugenommen, die bereitgestellt werden. Damit steigt der Bedarf an einer Automatisierung von Speicherverwaltungsaufgaben über alle Arten von Clustern, an die jeweils sehr unterschiedliche Speicherdienste angeschlossen sein können.
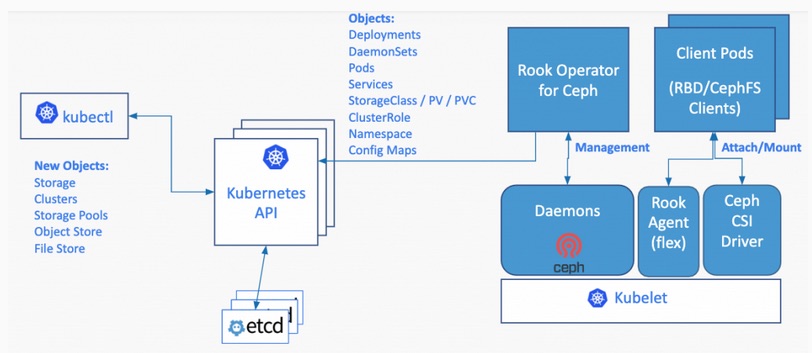
Abb. 1: Bildquelle Rook CNCF
Anmerkung: Rook verwandelt verteilte Speichersysteme in selbstverwaltende, selbstskalierende und selbstheilende Speicherdienste. Es automatisiert die Aufgaben von Speicheradministratoren hinsichtlich Bereitstellung, Bootstrapping, Konfiguration, Provisionierung, Skalierung, Upgrade, Migration, Disaster Recovery, Überwachung und Ressourcenmanagement. Rook nutzt dazu die Leistungsfähigkeit der Kubernetes-Plattform, um seine Dienste über einen Kubernetes Operator für jeden Speicheranbieter bereitzustellen.
Native Cloud-Technologien ermöglichen es, skalierbare Anwendungen in modernen, dynamischen Umgebungen wie öffentlichen, privaten und-/oder hybriden Clouds zu erstellen und auszuführen. Container, Servicenetze, Mikroservices, unveränderliche Infrastruktur sowie deklarative APIs veranschaulichen diesen Ansatz. Diese Techniken ermöglichen lose gekoppelte Systeme, die belastbar, handhabbar und zentral zu kontrollieren sind. In Kombination mit einer robusten Automatisierung ermöglichen sie es, mit minimalem Aufwand im laufenden Betrieb Änderungen vorzunehmen. Aus Speicherverwaltungs-Sicht sind in diesem Umfeld auf Open-Source-Technologie basierende neue Lösungen deshalb nicht zu unterschätzen. Diese integrieren Datei-, Block- und Objektspeicherdienste direkt im Applikations-Cluster und führen sie mit anderen Anwendungen bzw. Diensten zusammen, die den Speicher allokieren. Dadurch wird der Cloud-native Cluster autark und portabel über Public Clouds und On-Premise-Bereitstellungen hinweg. Unternehmen werden in die Lage zu versetzt, ihre Rechenzentren mit dynamischer Anwendungsorchestrierung für verteilte Speichersysteme in lokalen und öffentlichen Cloud-Umgebungen zu modernisieren.
Auch wenn Kubernetes verteilte Dateisysteme wie Network File System (NFS) und GlusterFS verwenden kann, ist der Einsatz einer Container-fähigen „Storage-Fabric“ sinnvoll, die auf die Anforderungen von zustandsabhängigen Workloads in der Produktion ausgelegt ist. Betreiber können aktuell aus einer wachsenden Anzahl von Open-Source-Projekten und kommerziellen Implementierungen wählen. Das Cloud-Native-Ökosystem hat über Container Storage Interface (CSI) Spezifikationen definiert, um einen standardisierten, portablen Ansatz zur Implementierung und Nutzung von Storage-Services durch containerisierte Workloads zu beschleunigen. Ceph, Longhorn, OpenEBS und Rook sind einige native Storage-Open-Source-Projekte, während Kubera von MayaData, Trident von NetApp, Portworx von Pure Storage oder die Container Storage Platform von Red Hat kommerziell verfügbare Support-Angebote darstellen. Bekannte Anbieter wie NetApp, Pure Storage, IBM, HPE, VMware etc. bieten ebenfalls Storage-Plugins für Kubernetes an. Tool-seitig ist ein neues Open-Source-Projekt wie Kubestr in der Lage, dazu die relativen Leistungswerte verschiedener Speicherkonfigurationen über Cloud-Anbieter hinweg zu analysieren.
Der Betrieb von Systemen in der Produktion beinhaltet steigende Anforderungen an Hochverfügbarkeit, Ausfallsicherheit und Wiederherstellung (RTO/RPO) nach einem Ausfall. Auch beim Betrieb von Cloud-nativen Anwendungen kann aber davon ausgegangen werden, dass CPU-Nodes ausfallen, Cluster-Knoten wegbrechen und Microservices-Instanzen mit hoher Wahrscheinlichkeit ausfallen, der Service aber trotzdem weiterlaufen soll. Ein modernes Datenmanagement sollte diese Anforderungen somit priorisieren.
Wenn die Speichersoftware von der Hardware getrennt wird, wird es für IT-Teams einfacher, Industriestandard-Laufwerke (NVMe, SAS etc.) einfach zu ersetzen, wenn sie es für erforderlich halten und die Trends in diesem Bereich zeigen die Richtung auf: Speichersysteme werden mittelfristig, genau wie andere IT-Infrastrukturplattformen, über Software bereitgestellt (Infrastructure as a code). Kostenseitig (OPEX) geht es allerdings aber nicht nur um die Unterschiede zwischen SAS-Drives und Flash, also die reinen Speicherkosten (CAPEX); ebenso müssen Storage-Server, Wartungs-, Strom- und alle Software-Lizenzkosten, die mit verschiedenen Speicherebenen oder auch Software Defined Storage Plattformen aus Speicherverwaltungssicht verbunden sind, mitberücksichtigt werden. Zusammengefasst lässt sich auf Basis der bisher geschildeten Randbedingungen eine Software-zentrierten Infrastruktur- und Datenverwaltung wie folgt beschreiben:
Als Plattform virtualisiert die Softwareschicht alle dazu notwendigen Speicher- und Netzwerk-Ressourcen (Beispiel: Container-as-a-Service-Plattform) und aggregiert diese logisch zusammen mit den jeweiligen Speicherebenen. Intelligente Datenverwaltungs-Software arbeitet KI-unterstützt im Hintergrund und automatisiert alle Arbeitsabläufe, die sonst manuell gesteuert werden müssten. Das verschlankt und beschleunigt IT-Prozesse, inkl. Monitoring- und Reporting. Darüber hinaus sind Funktionen wie Charge-back für die transparente Verrechnung der IT-Ressourcen verfügbar. Diese Entwicklung lässt sich gerade auch exemplarisch in verschiedenen Bereichen verfolgen:
Als Bestandteil von HCI mit Hypervisor-unabhängige SDS-Infrastrukturlösungen und Speicherverwaltungs-Funktionen.
Als Plattform für unstrukturierte Daten, die softwarebasierte, verteilte Filesysteme und Objektspeicher nutzen.
Als Cloud-nativer Speicher für containerisierte Anwendungsumgebungen; unterstützt zustandsabhängige Workloads innerhalb von Containern, indem er persistente Volumes bereitstellt.
Ein Fazit: IT-Organisationen sollten heute nicht mehr die reine Speicherverwaltung, sondern ihr Datenmanagement als strategischen Differenzierungsfaktor gegenüber Kunden, Mitbewerbern, Märkten und Anwendungen betrachten. Storage selbst wird in diesem Modell zu einem Service-bezogen (as-a-service) Dienst transformiert. Dieser Ansatz impliziert die Verwendung von Multi Cloud-Architekturen und verlangt den Einsatz von standardisierten Schnittstellen und hochintegrierten, software-gesteuerten Infrastrukturkomponenten (Infrastructure as a Code). Die Themen Hyperkonvergenz und der Einsatz von Cloud-nativen Technologien wird im Spannungsfeld von knappen Budget- sowie Personalressourcen und zunehmender Cloud-Komplexität jedenfalls in naher Zukunft für viele Unternehmen eine noch stärkere Aufmerksamkeit erfordern.