Starnberg, 03. Febr. 2022 - QLC-Flash, Storage Class Memory (SCM), Filesystem-Software und hochparallele Speicher-I/O-Architekturen für KI-Infrastrukturen...
Um was es hier geht: Datenwissenschaftler verbringen oftmals einen Großteil ihrer Zeit, geeignete Daten zu identifizieren, zu verwalten und entsprechend aufzubereiten, um brauchbare Datasets zu erstellen. Auch wenn die Automatisierung generell fortschreitet, fehlt dazu meist eine wichtige Vorbedingung, sprich die automatisierte Datenklassifizierung, um überhaupt brauchbare Basisdaten für KI-Projekte zu liefern. Aber es gibt eine weitere Herausforderung: "Gerne" wird - falls keine Cloud-Lösung gewählt wurde - die (on-premise) Datenverwaltung nebst der Speichertechnologie vernachlässigt, weil aus Sicht der Firmenleitung zu teuer, spezifisches Know-how nicht vorhanden bzw. dringend benötigte Ressourcen wie z.B. Fachkräfte oder Systeme fehlen. Dem entgegen steht jedoch die geforderte erfolgreiche Umsetzung von KI-Initiativen, die eigentlich aber nur über eine konsequente Modernisierung der Infrastruktur geleistet werden kann.
Diesen Blogpost als Podcast hören (8:50 min.) > https://podcasts.apple.com/de/podcast/storage-und-k%C3%BCnstliche-intelligenz/id81294878?i=1000551187982
Moderne Speichertechnologien leisten heute in Bezug auf ihre Leistung, Skalierbarkeit und Kapazität viel mehr als noch vor drei bis fünf Jahren, was sich wiederum auf alle wesentlichen Aspekte von KI-Projekten wie Datenpflege und -Management bis hin zum Datenbanken-Design positiv auswirken kann. Ein Beispiel: Bei Deep Learning (DL) Projekten bedeutet ein langsamer Speicher eine langsamere maschinelle Lernleistung, denn das Deep Neural Network stellt ein Abbild eines massiv parallelen vernetzten Modells dar, bei dem bis zu Milliarden von Neuronen lose miteinander verbunden werden, um ein einziges Problem zu lösen. GPUs wiederum sind massiv parallele Prozessoren, bei denen jeder einzelne aus Tausenden von lose gekoppelten Rechenkernen besteht, um 100x höhere Leistungswerte und mehr als eine Standard CPU zu erzielen.
Somit wird klar, dass für KI-Systeme ein hochleistungsfähiger Speicher erforderlich ist, um den GPU-Systemen eine entsprechend hohe "Ingest"-Bandbreite (X-Rate) für zufällige (random) Zugriffsmuster von kleinen bis großen Files zu liefern. Ein weiterer Punkt betrifft die I/O-Performanceseite und hier die „Random“ I/O Leseleistung bei geringer Warteschlangentiefe (queue depth). Random Reads stellen in der Regel rund 75% aller Transaktionen dar und sind eine wichtige Performancekennzahl.
Distributed Direct Attached (DAS) oder klassischer SAN Storage skaliert bei komplexeren KI-Anforderungen mit schnell wachsenden massiven Datensätzen nicht in der gewünschten Weise (Latency, OPEX, CAPEX).
- Zufällige (random) Leseleistung bei geringer Warteschlangentiefe und random writes sind Bereiche, bei dem aber auch NAND Flash SSD Storage und Flash JBODs allein und ohne Caching technologiebedingt keine guten Leistungswerte erzielen.
Ein Lösungsansatz ist die Bereitstellung von hochparallelen I/O -Speichersystem-Architekturen über Fabrics mit NVMe im Verbund mit einer hierfür optimierten Speicherverwaltung (scale-out filesysteme / s.a. z.B. NFS-Optimierungen etc.) nebst geeigneten Speichermedien = NAND Flash und Storage Class Memory (siehe unten):
NVMeoF und RDMA über InfiniBand bzw. 100 GBE für skalierbare Speicherpools sind Hardware- und Protokollseitig aus Storage- und Applikationssicht derzeit wichtige Protokolle für Low-latency, high Performance I/Os.
In Kombination mit kostenoptimiertem QLC-NAND Flash (Kapazität) und Storage Class Memory (Leistung) ergibt sich eine skalierbare Storage-Plattform zum Aufbau moderner Speicher- und Datenmanagement-Systeme für KI-Infrastrukturen. QLC deshalb, weil auf Grund der bei KI-Apps existierenden Read-to-write I/O-Ratio von bis zu 5000:1 (deep learning) - im Gegensatz zu 4:1 bei klassischen RZ-Anwendungen - die Haltbarkeit der NAND-Zellen (Wear-out) deutlich erhöht ist. Damit ist QLC auch robuster als SATA-HDDs, zumindest wenn deutlich mehr gelesen als geschrieben wird; ganz abgesehen von den höheren E/A-Leistungswerten (> SSD ca. 450 x schneller im I/O).
Mehr Leistungsvorteile mit Persistent Storage Class Memory, SCM
Storage Class Memory - als Produkt hier Intel® Optane™ auf Basis 3D XPoint (1) - soll bis zu ca. 6-fache Leistungswerte im Durchsatz gegenüber NAND-basierten SSDs liefern und eine über 60 x höhere I/O-Response time (Quelle: Intel); bei einer Random Read Queue Depth von 1-4; die Latenzzeiten liegen im Bereich von 7μs -10μs (reads, writes). Die Leistung von Speichersystemen wird mit SCM positiv beeinflusst und dies wiederum hilft beim Design von persistenten high-performance KI-Speicher-Infrastrukturen.
Die 3D XPoint SCM-Technologie ist leistungsmäßig deutlich über 3-D-NAND (aber unterhalb von DRAM) angesiedelt, so dass künftig eher der limitierende Faktor potentiell beim Server (bisheriges PCI-Bus Protokoll als bottleneck) liegen kann. Ein weiterer Vorteil betrifft die aus QoS-Sicht dauerhaft konstant hohe Lese- und Schreibleistung sowie die Haltbarkeit, d.h. bis zu 20-mal mehr Terabytes Written (TBW) gegenüber NAND.
Eine wichtige Entwicklung im High-Performance-Bereich ist in diesem Zusammenhang der Compute Express Link (CXL) als offener Standard für Hochgeschwindigkeitsverbindungen zwischen CPU und Speicher. CXL basiert auf PCIe und umfasst ein PCIe-basiertes Block-Input/Output-Protokoll (CXL.io) sowie neue cache-kohärente Protokolle für den Zugriff auf den System- (CXL.cache) und Gerätespeicher (CXL.mem).
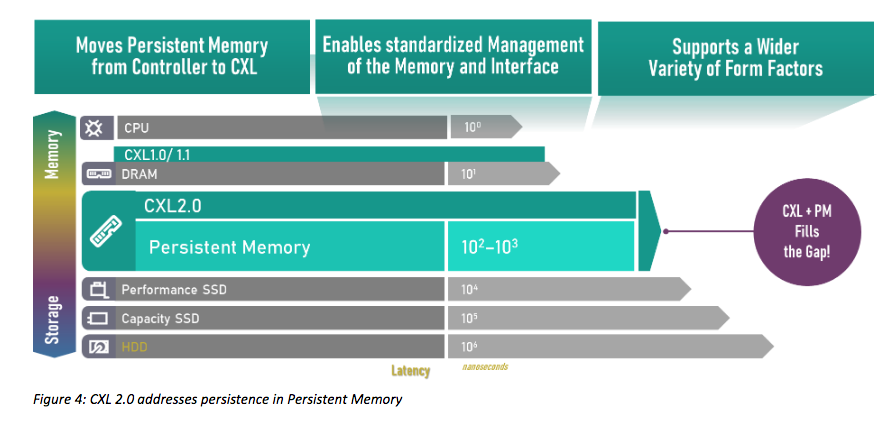
Abbildung: CXL 2.0 addresses persistence in Persistent Memory (Bildquelle / Alle Rechte: Compute Express Link™ 2.0. White Paper. Dr. Debendra Das Sharma, Intel Fellow and Director, I/O Technology and Standards, and Siamak Tavallaei, Principal Architect, Microsoft Azure Hardware Architecture Co-Chairs, Technical Task Force, CXL™ Consortium).
Link > https://www.computeexpresslink.org/
Compute Express Link (CXL) ist ein offener Industriestandard für Verbindungen mit hoher Bandbreite und niedriger Latenz zwischen dem Host-Prozessor und Geräten wie Beschleunigern, Memory Buffers und intelligenten E/A-Geräten. Damit ist der Standard laut Enwickler für Hochleistungs-Rechenlasten konzipiert, indem es heterogene Verarbeitungs- und Speichersysteme mit Anwendungen in den Bereichen künstliche Intelligenz, maschinelles Lernen und Analytik etc. unterstützt.
Ein Fazit
KI-Apps mit massiven Datensätzen verlangen nach skalierbarer hoher I/O-Leistung bei geringer Latenz zu vertretbaren Kosten. Hochparallele I/O-Architekturen und NVMeoF im Verbund mit QLC-NAND (künftig auch PLC = Penta-level-Cell), Storage Class Memory sowie skalierbarer Filesystem Software sind eine leistungsgerechte, als auch wirtschaftliche Alternative (OPEX) bei steigenden Apps-Anforderungen. CXL als sich rasch entwickelnder Standard seit 2019 (v.3.0 bereits in Arbeit) sollte weiter beobachtet werden.
Quellen: enterprisestorageforum.com / micron.com / intel.com
(1) Anmerkung: Die Entwicklung von 3D XPoint (Persistent) Memory bei Micron Technology (ursprünglich als gemeinsame Entwicklungsarbeit zwischen Micron und Intel) wurde im März 2021 offiziell eingestellt. Micron überlegt Gerüchten zufolge, kündtig neue SCM-Speicherprodukte - die auf Compute Express Link Technologie basieren - zu entwickeln.
Querverweis: