Starnberg, 24. Juli 2018 - Wie können Unternehmen über Innovationen im digitalen Zeitalter erfolgreich sein und welche Rolle spielt hierbei das Storage- und Daten Management...
Um was es hier geht: Damit Unternehmen angesichts des Wandels erfolgreich sind, müssen sie zwei kritische Aspekte beachten: einerseits vorhandene Ressourcen und Fähigkeiten durch Innovationen nutzen und andererseits in neue Märkte und Technologien investieren, in denen vorhandene Ressourcen bzw. Fähigkeiten direkte Wettbewerbsvorteile gegenüber dem Mitbewerb liefern. Gartner (1) hat zudem in Bezug auf die IT Organisation (ITO) und dem Spannungsfeld zwischen Entwicklung (dev) und Betrieb (ops) die Terminologie „Bi-modale IT“ eingeführt und daraus ergeben sich an den Storage und Daten-Management spezifische Anforderungen.
Während im klassischen Mode 1 primär Stabilität im Anwendungsbetrieb gefordert ist, gilt beim Mode 2 Agilität als oberste Priorität. Bei DevOps - Projekten im Zusammenhang mit Containern und Microservices wird dabei Storage als Software Definierte Lösung (SDS) für Block-, File- und Object interessant. Ein Vorteil hierbei liegt darin, dass der Anwender, der einen neuen Container deployed, sich nicht mehr an einen Storage Admin. wenden muss, falls er Speicherressourcen für sich beanspruchen möchte: jetzt initiiert er seinen Container (am Beispiel Openshift via Kubernetes), und bekommt den zugehörigen Storage Container automatisch gemapped.
SDS ist übrigens gut geeignet aufzuzeigen, dass im Kontext einer bi-modalen IT zwei Ziele immer im Auge behalten werden sollten: a) Beweglichkeit und b) Elastizität des Storage-Layers im laufenden Betrieb. Mehr Kapazität? Sie fügen diese einfach im laufenden Betrieb hinzu. Sie brauchen mehr Kapazität und haben keine Hardware zur Verfügung oder keinen Platz? Nutzen Sie weitere Ressourcen in der (Public-)Cloud, im laufenden Betrieb.
Damit können Unternehmen jederzeit auf sich verändernde Anforderungen reagieren. Soweit zur Theorie... nur ist die Integration des Storage im Sinne einer übergreifenden Architektur zwischen on-premise und Cloud in vielen Unternehmen bislang noch nicht gut gelöst. Dazu Chris Aniszczyk, COO der Cloud Native Computing Foundation: „Storage ist eine der wichtigsten Komponenten von Cloud Native Computing, aber persistente Speichersysteme laufen heute in der Regel außerhalb der nativen Cloud-Umgebungen.“
Eine aus meiner Sicht erwähnenswerte Entwicklung in diesem Umfeld stellt die open-source Initiative „Rook“ (2) dar: Rook bringt Datei-, Block- und Objektspeichersysteme in den Kubernetes-Cluster und führt sie mit anderen Anwendungen und Diensten zusammen, die den Speicher verbrauchen (s.a. Abb. 1 unten). Dadurch wird der Cloud-native Cluster autark und portabel über Public Clouds und On-Premise-Bereitstellungen hinweg. Das Projekt wurde entwickelt, um Unternehmen in die Lage zu versetzen, ihre Rechenzentren mit dynamischer Anwendungsorchestrierung für verteilte Speichersysteme in lokalen und öffentlichen Cloud-Umgebungen zu modernisieren.
Anstatt ein völlig neues Speichersystem zu bauen, konzentriert sich Rook darauf, produktiv erprobte Speichersysteme wie Ceph als verteilte Storagelösung in eine Reihe von Cloud-basierten Diensten zu verwandeln, die nahtlos auf Kubernetes laufen. Rook integriert sich dabei tief in Kubernetes und bietet Funktionen zu den wichtigen Themen wie Sicherheit, Richtlinien, Quoten, Lifecycle Management oder Ressourcenmanagement. Rook nutzt im Wesentlichen das „Operator-Pattern“, um Kubernetes zur Unterstützung von Speichersystemen zu erweitern. Es wurde laut Entwickler-Community ein Konzept für einen Speichercluster, einen Speicherpool, einen Objektspeicher und ein Dateisystem hinzugefügt, mit denen Kubernetes erweitert wurde.
Laut der Cloud Native Computing Foundation (3) ermöglichen es native Cloud - Technologien, skalierbare Anwendungen in modernen, dynamischen Umgebungen wie öffentlichen, privaten und hybriden Clouds zu erstellen und auszuführen. Container, Servicenetze, Mikroservices, unveränderliche Infrastruktur und deklarative APIs veranschaulichen danach diesen Ansatz. Diese Techniken ermöglichen lose gekoppelte Systeme, die belastbar, handhabbar und beobachtbar sind. In Kombination mit einer robusten Automatisierung ermöglichen sie es, häufig und vorhersehbar mit minimalem Aufwand Änderungen vorzunehmen.
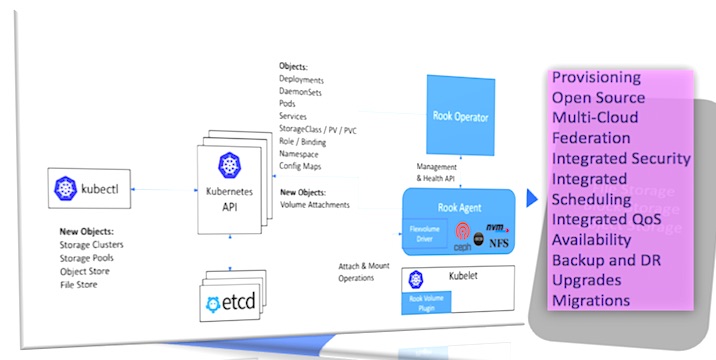
Abb. 1: Container Storage mit Kubernetes, Docker & Co. (Quelle: Rook, Cloud Native Computing Foundation, CNCF)
Ein Fazit: IT-Organisationen betrachten nicht mehr wie früher nur den Storage - sondern jetzt verstärkt IHRE DATEN - als strategischen Differenzierungsfaktor gegenüber Kunden, Mitbewerbern, Märkten repektive Anwendungen. Storage transformiert damit a la longue zu einem Service-bezogen (SLA/SLO/QoS) „Business centric Approach“, der Multi Cloud - Architekturen impliziert und auch on-premise möglichst auf standardisierten, wiederverwertbaren Infrastrukturkomponenten aufgebaut sein soll. Das Thema HCI (hyperkonvergente Infrastrukturen) wird in Zukunft damit eine stärkere Bedeutung erhalten; dies soll in einem meiner nächsten Beiträge hier dann genauer untersucht werden.
Quellenangabe:
(1) Link > Gartner Bi-modale IT
(2) Rook Project
(3) Cloud Native Computing Foundation (CNCF)