München, Starnberg, 12. Jan. 2024 - Eine Zusammenfassung wesentlicher Neuerungen von der AWS re:Invent 2023 im Nov./Dez. 23; NVIDIA-AWS KI-Project Ceiba u.v.m.…
Zum Hintergrund: Die AWS re:Invent 2023 vom 27.11. bis 01.12.2023 in Las Vegas (US), brachte eine Anzahl an Neuerungen von Produktankündigungen und Updates mit sich. Auf Grund des Umfangs finden Sie nachfolgend eine gekürzte Auswahl an Themen, Produkten und Lösungen, die der Anbieter im November und Dezember 2023 dazu vorgestellt hat. (1) Neben dem Bereich Bereich Datenbank und Analyse finden sich Lösungen wie Amazon ElastiCache Serverless, HPC-Infrastrukturen für Supercomputing mir Software-Lösungen und Diensten für generative KI in Kooperation mit NVIDIA, sowie die Zero-ETL-Integration von Amazon DynamoDB mit Amazon OpenSearch Service. Ziel ist es laut Anbieter, den Wert von Daten mit AWS besser erschließen können...
„AWS hat drei neue serverlose Neuerungen für sein Datenbank- und Analyseportfolio angekündigt, die es Kunden ermöglichen soll, ihre Dateninfrastruktur schneller und einfacher zu skalieren, um komplexe Anwendungsfälle zu unterstützen:
Amazon Aurora Limitless Database skaliert auf Millionen von Schreibtransaktionen pro Sekunde und verwaltet Petabytes an Daten. Basierend auf dem Datenmodells des Kunden verteilt die neue Funktionalität Daten und Abfragen automatisch auf mehrere Amazon Aurora Serverless-Instanzen, sodass keine benutzerdefinierte Software für die Verteilung von Anfragen über mehrere Datenbanken erstellt werden muss. Wenn die Rechen- oder Speicheranforderungen steigen, skaliert Amazon Aurora Limitless Database die Ressourcen automatisch vertikal und horizontal. Wartungsarbeiten und Änderungen können in einer einzigen Datenbank vorgenommen und automatisch auf alle Instanzen übertragen werden.
Mit Amazon ElastiCache Serverless sollen Kunden jetzt einen hochverfügbaren Cache in weniger als einer Minute bereitstellen können, ohne sich um Infrastruktur oder Konfiguration zu kümmern. Amazon ElastiCache Serverless macht den komplexen, zeitaufwändigen Prozess der Kapazitätsplanung überflüssig, indem es die Rechen-, Speicher- und Netzwerkauslastung eines Cache kontinuierlich überwacht und sofort vertikal und horizontal skaliert, um die Nachfrage ohne Ausfallzeiten oder Leistungseinbußen zu erfüllen. Mit Amazon ElastiCache Serverless müssen Kunden ihre Caches nicht mehr nachjustieren oder feinabstimmen.
Amazon ElastiCache Serverless repliziert Daten automatisch über mehrere Verfügbarkeitszonen und bietet Kunden eine Verfügbarkeit von 99,99 Prozent für alle Arbeitslasten. Kunden zahlen nur für die Daten, die sie speichern, und die Rechenleistung, die ihre Anwendung nutzt. Amazon ElastiCache Serverless ist ab sofort in Varianten für Redis und Memcached allgemein verfügbar.
Eine neue Funktionalität für Amazon Redshift Serverless nutzt KI, um Muster in Arbeitslasten entlang von Dimensionen wie Abfragekomplexität, Datengröße und Abfragehäufigkeit zu erlernen, und passt die Kapazität basierend auf diesen dynamischen Mustern kontinuierlich an, um vom Kunden vorgegebene Preis-Leistungs-Ziele zu erreichen. Amazon Redshift Serverless passt jetzt die Ressourcen auf der Grundlage dieser Arbeitslastmuster auch proaktiv an. Beispielsweise senkt Amazon Redshift Serverless mit KI-gesteuerter Skalierung und Optimierung automatisch die Kapazität während des Tages, um Dashboard-Arbeitslasten zu bewältigen, fügt aber bei Bedarf genau die richtige Menge an erforderlicher Kapazität hinzu, wenn eine komplexe Abfrage verarbeitet werden muss.
Über Nacht erhöht Amazon Redshift Serverless dann wieder proaktiv die Kapazität, um große Datenverarbeitungsaufgaben ohne manuelle Eingriffe zu unterstützen. Aufbauend auf den bestehenden Selbstoptimierungsfunktionen misst und passt Amazon Redshift Serverless automatisch Ressourcen an und führt eine Kosten-Nutzen-Analyse durch, um die beste Optimierung für eine bestimmte Arbeitslast zu priorisieren. Amazon Redshift Serverless mit KI-gesteuerter Skalierung und Optimierungen ist als Preview verfügbar.
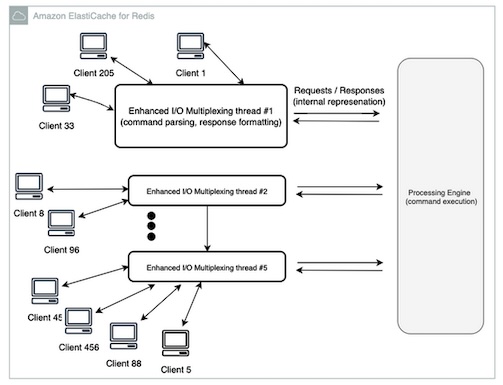
Abb: ElastiCache for Redis Version 7.1 (Bildquelle: Amazon)
Quelle / externer Link > https://aws.amazon.com/de/elasticache/features/#Serverless
AWS zeigt mit Graviton4 die nächste Generation von selbst entwickelten Chip
AWS Graviton4 ist der leistungsstärkste und energieeffizienteste AWS-Prozessor bisher für eine breite Palette von Cloud-Workloads. AWS Trainium2 soll die höchste Rechenleistung bei AWS für das Training von Basismodellen ermöglichen. Unter den Kunden, die die neuen von AWS entworfenen Chips nutzen, befinden sich Anthropic, Databricks, Datadog, Epic, Honeycomb und SAP.
WS Graviton4 und AWS Trainium2 bieten Fortschritte im Preis-Leistungs-Verhältnis und Energieeffizienz für eine breite Palette von Kunden-Workloads, einschließlich Training von Machine Learning- (ML) und generativen KI-Anwendungen. Graviton4 und Trainium2 stehen für die neuesten Innovationen im Chip-Design von AWS. Mit jeder aufeinanderfolgenden Chip-Generation bietet AWS ein besseres Preis-Leistungs-Verhältnis und mehr Energieeffizienz, was den Kunden zusätzliche Optionen eröffnet – neben Kombinationen von Chips/Instanzen mit den neuesten Chips von Drittanbietern wie AMD, Intel und NVIDIA – um praktisch jede Anwendung oder jeden Workload auf der Amazon Elastic Compute Cloud (Amazon EC2) auszuführen.
Graviton4 bietet bis zu 30 Prozent bessere Rechenleistung, 50 Prozent mehr Kerne und 75 Prozent mehr Speicherbandbreite als die aktuellen Graviton3-Prozessoren. Trainium2 wurde entwickelt, um bis zu viermal schnelleres Training als die Trainium-Chips der ersten Generation zu bieten und kann in EC2 UltraClusters mit bis zu 100.000 Chips eingesetzt werden. Dadurch wird es möglich, Basismodelle (Foundation Models, FMs) und große Sprachmodelle (Large Language Models, LLMs) in einem Bruchteil der Zeit zu trainieren, wobei die Energieeffizienz um das bis zu zweifache verbessert wird.
Kunden wie Datadog, DirecTV, Discovery, Formula 1 (F1), NextRoll, Nielsen, Pinterest, SAP, Snowflake, Sprinklr, Stripe und Zendesk nutzen Graviton-basierte Instanzen, um eine Vielzahl von Workloads auszuführen, darunter Datenbanken, Analysen, Webserver, Stapelverarbeitung, Ad-Serving, Anwendungsserver und Microservices. Außerdem wünschen sich die Kunden energieeffizientere Optionen für ihre Workloads, um die Auswirkungen auf die Umwelt zu reduzieren. Graviton wird von vielen Managed Services von AWS unterstützt, darunter Amazon Aurora, Amazon ElastiCache, Amazon EMR, Amazon MemoryDB, Amazon OpenSearch, Amazon Relational Database Service (Amazon RDS), AWS Fargate und AWS Lambda, wodurch die Vorteile von Gravitons Preis-Leistungs-Verhältnis für die Benutzer dieser Dienste zugänglich gemacht werden.
Graviton4-Prozessoren bieten bis zu 30 Prozent bessere Rechenleistung, 50 Prozent mehr Kerne und 75 Prozent mehr Speicherbandbreite als Graviton3. Graviton4 setzt auch in puncto Sicherheit Maßstäbe, indem alle physischen Hochgeschwindigkeits-Hardware-Schnittstellen vollständig verschlüsselt werden. Graviton4 wird in den speicheroptimierten Amazon EC2 R8g-Instanzen verfügbar sein, was es Kunden ermöglicht, die Ausführung ihrer High-Performance-Datenbanken, In-Memory-Caches und Big Data Analytics-Workloads zu verbessern.
R8g-Instanzen bieten leistungsstärkere Instanzgrößen mit bis zu dreimal mehr vCPUs und dreimal mehr Speicher als Instanzen der aktuellen Generation (R7g). Dies ermöglicht es Kunden, größere Datenmengen zu verarbeiten, ihre Workloads zu skalieren, die Wartezeit zu verbessern und die Gesamtbetriebskosten zu senken. Graviton4-basierte R8g-Instanzen stehen laut AWS ab sofort als Preview zur Verfügung, die allgemeine Verfügbarkeit ist für die kommenden Monate geplant.
Die Trainium2-Chips sind speziell für hochleistungsfähiges Training von FMs und LLMs mit bis zu Billionen von Parametern konzipiert. Trainium2 wurde entwickelt um eine bis zu viermal schnellere Trainingsleistung und eine dreimal höhere Speicherkapazität im Vergleich zu den Trainium-Chips der ersten Generation zu liefern, bei gleichzeitiger Verbesserung der Energieeffizienz (Leistung/Watt) um bis zu zweimal.
Trainium2 wird in Amazon EC2 Trn2-Instanzen verfügbar sein, die 16 Trainium-Chips in einer einzigen Instanz enthalten. Trn2-Instanzen sollen es Kunden ermöglichen, bis zu 100.000 Trainium2-Chips in UltraClusters der nächsten Generation von EC2 zu skalieren, die via AWS Elastic Fabric Adapter (EFA) zu einem Petabit-Netzwerk verbunden sind und bis zu 65 Exaflops an Rechenleistung liefern können. Kunden erhalten so „on demand“ Zugriff auf Rechenleistung auf Supercomputer-Niveau. Mit diesem Maß an Skalierbarkeit können Kunden ein LLM mit 300 Milliarden Parametern in Wochen statt Monaten trainieren. Durch die Bereitstellung der höchsten Skalierungsleistung für ML-Training zu erheblich niedrigeren Kosten können Trn2-Instanzen Kunden dabei unterstützen, die nächste Welle von Fortschritten in der generativen KI zu erschließen und zu beschleunigen.
SAP HANA Cloud als Cloud-native In-Memory-Datenbank ist ein wichtiger Bestandteil der SAP Business Technology Platform (SAP BTP). Dazu Jürgen Müller, CTO und Mitglied des Vorstands der SAP SE: „Kunden verlassen sich auf SAP HANA Cloud, um ihre geschäftskritischen Prozesse und intelligenten Datenanwendungen der nächsten Generation in der Cloud auszuführen. Im Rahmen des Migrationsprozesses von SAP HANA Cloud auf AWS Graviton-basierte Amazon EC2-Instanzen haben wir bereits eine bis zu 35 Prozent bessere Preisleistung für analytische Workloads festgestellt. Wir freuen uns darauf, Graviton4 in den kommenden Monaten zu validieren und die Vorteile zu ermitteln, die es unseren gemeinsamen Kunden bringen kann.“
AWS und NVIDIA haben angekündigt, ihre strategische Zusammenarbeit auszuweiten. Der Fokus liegt auf der Bereitstellung von fortschrittlicher Infrastruktur, Software und Diensten, mit denen Kunden ihre Innovationen im Bereich der generativen künstlichen Intelligenz vorantreiben können. Hier einige Eckpunkte der Zusammenarbeit:
AWS wird die NVIDIA GH200 Grace Hopper Superchips mit der neuen NVLink-Technologie in die Cloud bringen. NVIDIA GH200 NVL verbindet 32 Grace Hopper Superchips mit NVIDIA NVLink- und NVSwitch-Technologien in einer Instanz. Die Plattform wird auf Amazon Elastic Compute Cloud (Amazon EC2)-Instanzen verfügbar sein, die mit dem leistungsfähigen Netzwerk von AWS verbunden sind (EFA), durch fortschrittliche Virtualisierung (AWS Nitro System) unterstützt und in Hyperscale-Clustern namens Amazon EC2 UltraClusters bereitgestellt werden – was Kunden die Skalierung auf Tausende von GH200 Superchips ermöglicht.
NVIDIA und AWS planen zusammenarbeiten, um NVIDIA DGX Cloud, NVIDIAs AI-Training-as-a-Service, auf AWS zu hosten. Es wird die erste DGX Cloud mit GH200 NVL32 sein, die Entwicklern den größten gemeinsamen Speicher in einer einzigen Instanz bietet. DGX Cloud auf AWS wird das Training modernster generativer KI und großer Sprachmodelle (Large Language Models, LLMs) beschleunigen, die mehr als eine Billion Parameter erreichen können.
NVIDIA und AWS arbeiten im Rahmen von Project Ceiba zusammen, um den weltweit schnellsten GPU-gestützten KI-Supercomputer zu bauen, ein System mit GH200 NVL32 und Amazon EFA-Interconnect, das von AWS für NVIDIAs eigenes Forschungs- und Entwicklerteam gehostet wird. Dieser einzigartige Supercomputer – mit 16.384 NVIDIA GH200 Superchips und einer Rechenleistung von 65 Exaflops – wird von NVIDIA genutzt, um die nächste Welle an generativer KI-basierten Innovationen voranzutreiben.
AWS plant drei zusätzliche Amazon EC2-Instanzen auf Basis von NVIDIA GPUs einführen:
- P5e-Instanzen basierend auf NVIDIA H200 Tensor Core GPUs, optimiert für groß angelegte und innovative Arbeitslasten im Bereich der generativen KI und des High Performance Computing (HPC).
- G6- und G6e-Instanzen auf Basis von NVIDIA L4 GPUs bzw. NVIDIA L40S GPUs für eine breite Palette von Anwendungen wie KI-Feinabstimmung, Inferenz, Grafik- und Video-Arbeitslasten; G6e-Instanzen eignen sich besonders für die Entwicklung von 3D-Workflows, digitalen Zwillingen und anderen Anwendungen mit NVIDIA Omniverse, einer Plattform für die Verbindung und Erstellung von generativen KI-gestützten 3D-Anwendungen.
NVIDIA kündigt Software auf AWS an, um die Entwicklung von Anwendungen auf Basis von generativer KI zu fördern: Der NVIDIA NeMo Retriever Microservice bietet neue Tools zur Erstellung hochpräziser Chatbots und Zusammenfassungs-Werkzeuge auf Basis beschleunigter semantischer Suche.
NVIDIA BioNeMo, das auf Amazon SageMaker verfügbar ist und künftig auf AWS in NVIDIA DGX Cloud angeboten werden soll, ermöglicht es Pharmaunternehmen, die Arzneimittelforschung zu beschleunigen, indem sie das Training von Modellen mit ihren eigenen Daten vereinfachen und beschleunigen. So nutzt AWS das NVIDIA NeMo-Framework, um ausgewählte Amazon Titan LLMs der nächsten Generation zu trainieren. Amazon Robotics hat begonnen, NVIDIA Omniverse Isaac zu nutzen, um digitale Zwillinge für die Automatisierung, Optimierung und Planung seiner autonomen Lagerhäuser zu erstellen, bevor diese in der realen Welt eingesetzt werden.
Zero-ETL: AWS hat vier neue Integrationen angekündigt, die es Kunden ermöglichen soll, Daten aus verschiedenen relationalen und nicht-relationalen Datenbanken schnell und einfach zu verbinden und zu analysieren, ohne komplexe ETL-Datenpipelines (Extract, Transform, Load) erstellen und verwalten zu müssen:
Zero-ETL-Integrationen für Amazon Aurora PostgreSQL, Amazon DynamoDB und Amazon RDS for MySQL mit Amazon Redshift: Mit diesen Integrationen können Kunden in Amazon Redshift schnell und einfach auf Daten aus beliebten relationalen und nicht-relationalen Datenbanken zugreifen und diese umfassend analysieren, ohne zuerst aufwändige ETL-Pipelines aufbauen zu müssen. Die Zero-ETL-Integrationen sind als Preview verfügbar und ergänzen die bereits verfügbare Zero-ETL-Integration für Amazon Aurora MySQL.
Zero-ETL-Integration von Amazon DynamoDB mit Amazon OpenSearch Service: Diese Integration erleichtert es Kunden, leistungsstarke Volltext- und Vektorsuchabfragen für ihre DynamoDB-Daten nahezu in Echtzeit durchzuführen. Kunden wählen einfach die DynamoDB-Tabellen aus, welche Daten enthalten, die sie analysieren möchten. Innerhalb von Sekunden, nachdem sie in DynamoDB geschrieben wurden, werden diese Daten dann in OpenSearch Service repliziert. Kunden können Daten aus mehreren DynamoDB-Tabellen mit einem von OpenSearch Service verwalteten Cluster oder einer „Sammlung“ in OpenSearch Serverless synchronisieren, um ganzheitliche Einblicke über mehrere Anwendungen hinweg zu gewinnen und ihre Suchressourcen zu konsolidieren, was ihre Kosten senkt und gleichzeitig die betriebliche Effizienz erhöht. Zu den Kunden, die auf Zero-ETL-Integrationen von AWS setzen, zählen Grabyo, iCIMS, Kaplan, Muzz, Orion Advisor Solutions und United Airlines."
(1) Zugehörige Quellen und weitere Informationen zur re:Invent 2023 finden sich auch direkt beim Anbieter unter diesem externen Bloglink > https://aws.amazon.com/de/blogs/aws/category/events/reinvent/
Querverweis:
Unser Beitrag > AWS Cloud für Europa: Amazon Web Services startet neue AWS European Sovereign Cloud
Unser Beitrag > Was unterscheidet Cloud von Cloud-enabled und Cloud-native Computing?