München, Starnberg, 04. Mai 2020 - Wie lassen sich Daten aus Backups, Archiven, usw. analysieren und automatisieren? Ein Gastbeitrag zu Commvault Activate- und 4D Index…
Zum Hintergrund: Die Datenmengen bei Unternehmen und Organisationen wachsen in Zeiten der Digitalisierung beständig und können manuell meist nicht mehr vernünftig bearbeitet werden. IT-Teams brauchen somit die Automatisierung, um manuelle und sich wiederholende arbeitsaufwändige Prozesse zu beseitigen. Mit den richtigen Verfahren lassen sich Daten schneller und weniger fehleranfällig verwalten und die IT wird entlastet. Ein hoher Grad an Automatisierung macht das Datenmanagement zudem zukunftssicherer, flexibler und einfacher in der Verwaltung. Wie aber lassen sich Daten aus Backups, Archiven oder Live-Quellen konkret analysieren und automatisiert Regeln auf diese Daten anwenden? Herr Olaf Dünnweller - Area Vice President Germany Geschäftsführer Commvault Systems GmbH VP Sales bei Commvault - einem Anbieter von Backup, Recovery und Archivierung in hybriden IT-Umgebungen, geht dieser Frage für Sie in seinem folgenden Gastbeitrag nach.
Zum Gastbeitrag (unkommentiert, gibt die Meinung des Verfassers wieder): "Die Daten Ihres Unternehmens gleichen der Spitze eines Eisbergs, vieles liegt im Verborgenen, was verhindert, dass „Insights" für Innovationen zur Verfügung stehen. Aus Compliance-Sicht stellt das zugleich ein Risiko dar. Irgendwann sind Verantwortliche gezwungen, unter die Wasseroberfläche zu tauchen: Nämlich dann, wenn sich das gesetzliche Rahmenwerk ändert, neue Manager sich die Zahlen ansehen oder Daten der Nachlässigkeit von Mitarbeitern oder Cybercrime zum Opfer fallen. Wie aber genau lassen sich Daten aus Backups, Archiven oder Live-Quellen analysieren und automatisiert Regeln auf diese Daten anwenden? Bei Commvault ist dieser Service Teil des Werkzeugsets „Activate“. Der darin enthaltende dynamische 4D-Index greift auf künstliche Intelligenz (KI) zurück, um das Verständnis für Daten über Datenquellen und Datentypen hinweg zu optimieren. Stichwort: Sensitive Data Governance, d.h. mithilfe von Automatisierung Compliance-Prozesse steuern.
- Erkennung und Risikobewertung von sensiblen Daten über unstrukturierte Daten hinweg.
- Erstellung von Risikoprofilen, um Pläne zur Risikominderung bei Datenüberlastung zu priorisieren.
- Proaktive Bereinigung unnötiger personenbezogener Daten, direkt aus der Datenquelle sowie aus eventuellen Sicherungskopien.
- Überprüfungs- und Genehmigungsverfahren zurUnterstützung der gemeinsamen Entscheidungsfindung von IT und Geschäftseinheiten.
Unternehmen erhalten dadurch mehr Informationen über ihre Daten, unabhängig davon, ob sie mit Werkzeugen von Drittanbietern, Commvault-Tools oder bislang überhaupt nicht verwaltet werden. Wenn „Commvault Activate“ gemeinsam mit „Commvault Complete Backup & Recovery“ verwendet wird, können Kunden das gewonnene Datenwissen in die indexierte Sammlung von Backup- und Archivdaten-Instanzen einbinden. Dies führt zu einer vollständig virtualisierten Datenlandschaft. Im 4D-Index sind namentlich alle Daten zu finden, die über die Backup- und Recovery-Plattform verwaltet oder definiert werden. Er deckt vier Aspekte ab, die für ein gutes Datenmanagement essenziell sind: 1. grundlegende Metadaten 2. Indexierung 3. Klassifikation 4. Advanced Insights.
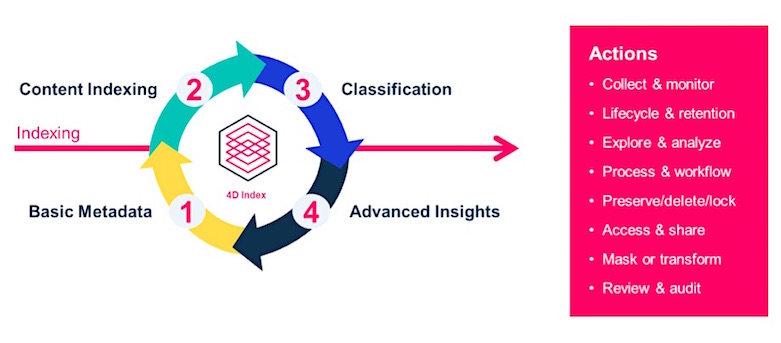
Abb.1: Vier Aspekte des dynamischen 4D-Index (Bildquelle: Commvault)
1. Grundlegende Metadaten
Bei regelmäßigen Backups und Archivierungen werden grundlegende Metadaten über die entsprechenden Daten gesammelt und in den Index geladen, die für die Datenwiederherstellung wichtig sind. Die Metadaten für eine E-Mail könnten Elemente wie Betreff, von, an, Datum des Versands, Empfangsdatum, Größe usw. sein. Bei einer Datei könnte es sich um Pfad, Speicherort, Größe, Erstellungsdatum, Änderungsdatum, Ersteller, letzter Bearbeiter handeln.
2.Indexierung von Inhalten
Zusätzlich zur Volltextindexierung lassen sich Daten aus Office-Dateien, E-Mails, PDF-Dateien und einer Vielzahl anderer unstrukturierter, halbstrukturierter und strukturierter Datenquellen in weitere Metadatenfelder innerhalb des Index laden. Nach dieser Vorarbeit lassen sich Suchen nach Schlüsselwörtern oder Phrasen durchführen oder Archivierungsrichtlinien anwenden. In der Kombination mit der richtigen Lösung lassen sich sogar Datenquellen indexieren, die sich „live" in Produktionssystemen befinden.
3. Klassifikation
Um sensible Daten zu verwalten und Datenrisiken zu mindern, werden diese klassifiziert. Dabei werden Eigenschaften und Informationen in Dateien identifiziert, so dass diese Dateien Kategorien (Klassen) zugeordnet werden können. Ein Beispiel für ein sensibles Dokument ist ein Ausweisdokument. Ein Administrator könnte z. B. ein Muster für ein Führerscheinformat definieren. Bei der Inhaltsindexierung werden Volltexte danach durchsucht, ob sie mit dem Muster übereinstimmen, und in diesem Fall folgt einen Eintrag in Metadatenfeldern. Anschließend lässt sich nach bestimmten Führerscheinnummern oder nach Dateien suchen, die aussehen, als könnten sie eine Führerscheinnummer enthalten.
4. Advanced Insights
Verschiedene intelligente Algorithmen von Technologiepartnern wie Microsoft, Google und AWS helfen dabei, den Index anzureichern. Künstliche Intelligenz gibt es in vielen Formen, und ob es sich nun um statistische, wie maschinelles Lernen (ML), semantische, wie natürliche Sprachverarbeitung (NLP) oder andere KI-Techniken handelt – das Ziel ist es, die Informationen über Daten anzureichern, um Daten besser durchsuchbar, zugänglich, nutzbar zu machen. Wenn alle vier Bereiche gut umgesetzt und miteinander verknüpft werden, lassen sich einige leistungsstarke Szenarien verwirklichen, um Daten nicht nur intelligent zu finden und zu verwalten, sondern auch zu visualisieren und einen zusätzlichen Wert daraus abzuleiten. So könnte das System aus früheren Suchen lernen und bei der Ausgabe von künftigen Suchergebnissen berücksichtigen, ob die Dokumente zuvor tatsächlich aufgerufen wurden, ob also die Suchbegriffe mit den tatsächlich konsumierten Inhalten übereinstimmen.
Fazit
Sekündlich werden sowohl flüchtige als auch dauerhaft genutzte Daten generiert. Ob sie einen Nutzen haben, liegt daran, ob und wie schnell sie genutzt werden. Da weiterhin Menschen die geschäftskritischen Entscheidungen treffen, fällt dem dynamischen Index die Rolle zu, das Wissen über Datenbestände zu verbessern, Verbindungen herzustellen und Daten besser zugänglich zu machen. Immer neue Schnittstellen ermöglichen die Inventarisierung und Indexierung von Daten aus Quellen wie Online-Datenspeichern, aktiven Endgeräten oder neuen O365-SaaS-Cloud-Datenspeichern. Damit können Daten im Rahmen einer ganzheitlichen, unternehmensweiten Betrachtung ausgewertet werden."
Querverweise zum Thema: