München, Starnberg, 04. Aug. 2022 - Weshalb herkömmliche Datenarchitekturen durch Digitalisierung und KI immer schneller an Grenzen stoßen; ein Gastbeitrag von Denodo...
Zum Hintergrund: Unternehmen verfügen über immer größere Mengen an Daten. Herkömmliche Datenarchitekturen kommen damit an ihre Grenzen. Eine Lösung: Datenvirtualisierung als logische Schicht, die Unternehmensdaten über alle Systeme hinweg integriert. Auch beim Einsatz von KI scheitern herkömmliche Technologien zur Datenintegration oft daran, konsolidierten Daten für AI/ML in Echtzeit bereitzustellen. Die Datenvirtualisierung kann dieses Hindernis überwinden: Dazu werden die Datenkonsumenten von den Datenquellen entkoppelt und eine einzige logische Datenschicht für den Zugriff geschaffen. Durch diese Fähigkeit kann die Datenvirtualisierung komplexe, heterogene Datenarchitekturen mit Enterprise KI verbinden. Doch noch immer ranken sich einige Vorurteile um den Einsatz dieser Lösung. Otto Neuer, Regional Vice President und General Manager bei Denodo (1) nimmt dazu aus seiner Sicht im folgenden Gastbeitrag an Hand von fünf Beispielen konkret Stellung:
1. Datenvirtualisierung ist mit komplexen Abfragen auf großen Datenmengen überfordert
"Hintergrund: Noch vor einigen Jahren wurde Data Federation genutzt, um auf Daten aus verschiedenen Quellen zuzugreifen, ohne diese dabei zu kopieren. Allerdings wurden die Daten dabei nicht remote verarbeitet, sondern dafür in den Federation Server gezogen. Dies funktionierte nur schlecht bei der Verarbeitung großer Datenmengen oder komplexer Abfragen.
- Realität: Lösungen für Datenvirtualisierung wie die Denodo Platform schreiben Anfragen so um, dass die Verarbeitung dorthin verlagert wird, wo sich die Daten befinden. Deshalb müssen große Datenmengen erst gar nicht erst durch das System bewegt werden. Zudem wird die Performance bei Abfragen für langsamere Datenquellen verbessert, indem zwischengespeicherte Daten aus dem Cache verwendet werden. Moderne Plattformen für Datenvirtualisierung sind daher durchaus in der Lage, komplexe Abfragen auf großen Datenmengen sehr schnell zu verarbeiten.
2. BI-Tools und Datenvirtualisierung sind austauschbar
Hintergrund: Business-Intelligence-Tools bieten heute Funktionen für Data Blending, also um Daten aus verschiedenen Quellen miteinander zu kombinieren, zu bearbeiten und zu analysieren sowie daraus Reports für das Business zu erstellen. Zudem verfügen manche Tools auch über Funktionen für Data Modeling.
- Realität: Zwar ermöglichen BI-Tools Data Blending und Reports. Sie sind aber in ihrer Funktionalität eingeschränkt, denn jedes Tools benötigt sein eigenes semantisches Datensilo. Die Verbindung zwischen unterschiedlichen Tools ist nicht gegeben, sodass Data Blending auf das Tool eines spezifischen Anbieters ausgerichtet ist. Datenvirtualisierung ist jedoch in der Lage, Daten aus nahezu allen Quellen mit einer Vielzahl von Konsumenten und Tools in einem unternehmensweiten Data-Fabric-Layer zu verbinden.
3. Wer einen Data Lake hat, braucht Datenvirtualisierung nicht
Hintergrund: Data Lakes waren ursprünglich als Möglichkeit gedacht, um Daten, die typischerweise nicht in Datenbanken gespeichert sind, zu explorieren und nutzbar zu machen. Heute werden dort dagegen alle Unternehmensdaten gespeichert, analysiert und verarbeitet.
- Realität: Data Lakes sind äußerst komplex. So sind dort häufig gar nicht alle Daten gespeichert, auch weil sich nicht alle Daten hineinkopieren lassen. Zudem verfügen Unternehmen oft über mehrere Data Lakes. Außerdem fehlt ihnen eine entscheidende Komponente, um für eine breite Anzahl an Nutzern überhaupt hilfreich zu sein – Data Delivery Services. Statt einfach auf die Daten zugreifen zu können, müssen Nutzer sie erst selbst im Data Lake finden. Datenvirtualisierung bietet dagegen Zugriff auf Daten aus Data Lakes und anderen Quellen in einer einzigen einheitlichen Schicht und hilft Nutzern mit einem Data Catalog, Daten im Data Lake zu finden und verstehen.
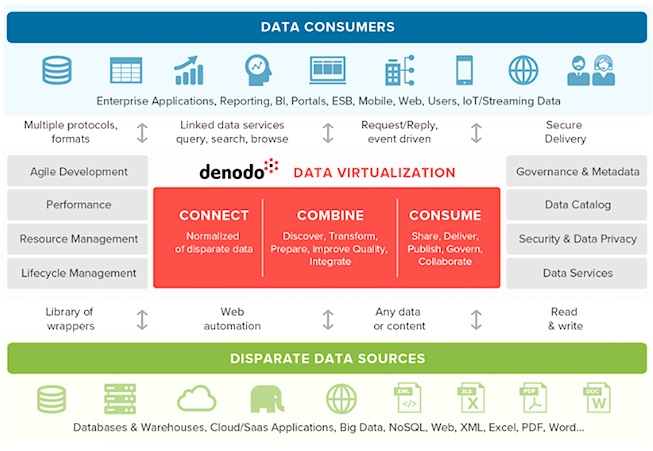
Abb. 1: Datenvirtualisierung- Übersichtsschaubild (Bildquelle: Denodo).
4. Wer ETL-Tools nutzt, braucht Datenvirtualisierung nicht
Hintergrund: Unternehmen können mithilfe von ETL-Tools Daten aus verschiedenen Quellen extrahieren, transformieren und dann in eine Datenbank oder ein Data Warehouse laden.
- Realität: ETL-Pipelines sind fragile Strukturen – kommt beispielsweise eine neue Datenquelle hinzu, bauen Unternehmen lieber eine neue Pipeline als die bestehenden zu verändern. Das führt einerseits zu Datensilos, was es für Nutzer schwieriger macht, benötigte Daten schnell zu finden und zu verarbeiten. Andererseits führt es zu Datenduplikaten, ein durchschnittliches Unternehmen hat zwölf oder mehr Kopien seiner Daten, die verteilt in der gesamten Architektur liegen. Bei Datenvirtualisierung verbleiben die Daten dagegen dort, wo sie sind, und werden nur in einer virtuellen Schicht dargestellt. Das spart Arbeit, Zeit und Speicherplatz.
5. Datenvirtualisierung führt zu einem Kontrollverlust bei den Daten
Hintergrund: Datenvirtualisierung gibt allen Mitarbeitern Zugriff auf Unternehmensdaten, damit sie Analysen per Self-Service schnell und einfach selbst ausführen können. Damit geht aber der Überblick verloren, wer welche Daten wie nutzt. Außerdem fehlt vielen Mitarbeitern das Verständnis dafür, wie sich Anfragen auf Backend-Systeme auswirken und welche Kosten sie womöglich verursachen.
- Realität: Plattformen für Datenvirtualisierung bieten zahlreiche Kontroll- und Governance-Funktionen, um den Zugang auf granularer Ebene zu regeln, für die Einschränkung von Anfragen – was beispielsweise Dauer, Prioritäten oder Zeilen im Ergebnis betrifft – und um den Umfang von Anfragen einzugrenzen, etwa durch die Nutzung von Filtern. Unternehmen können auch standardisierte, kuratierte Daten für die Analysen ihrer Mitarbeiter bereitstellen."

(1) Das Foto zeigt Otto Neuer, Regional Vice President und General Manager bei Denodo (Bildquelle: Denodo)
Querverweis:
Unser Beitrag > Künstliche Intelligenz im Unternehmenseinsatz benötigt zuverlässige Echtzeit-Daten
Unser Beitrag > Sicherheitsbedenken und Datensilos bremsen fast zwei Drittel der Automatisierungsinitiativen