Frankfurt/M., Starnberg, 02. Aug. 2023 - Kombiniert Storage-, Datenbank- und virtualisierte Compute Engine Services innerhalb eines skalierbaren Systems; Datengrundlage für DL...
Zur Ankündigung: VAST Data hat gestern offiziell seine neue und transformative VAST Data Platform vorgestellt. Das System wurde von Grund auf für die Zukunft der KI entwickelt. Anspruchsvolle KI-Anwendungen benötigen idealerweise eine Datenplattform, die Datenverwaltung und -verarbeitung in einem einheitlichen Stack vereinfacht. Bereits existierende Datenplattformen sind zwar in der Lage, die Anwendungskomplexität teils erheblich zu reduzieren. Dies gilt jedoch laut Jeff Denworth - Co-Founder von VAST Data - nicht für die Anforderungen von Deep Learning-Anwendungen der nächsten Generation. (1)
Der Hintergrund: Die nächste Generation von KI-Infrastruktur muss hierfür parallelen Filezugriff, GPU-optimierte Leistung für das Training neuronaler Netze und Inferenzen auf unstrukturierten Daten sowie einen globalen Namensraum bereitstellen, der hybride Multi-Cloud- und Edge-Umgebungen abdeckt. Dies alles integriert in einem möglichst einfach zu verwaltenden und automatisierten Angebot, das (föderiertes) Deep Learning ermöglicht. Anmerkung: föderiertes Deep Learning bedeutet, dass jedes Gerät ein lokales Model trainiert und nur das Modell-Update überträgt. Die Daten selbst verbleiben am Ursprungsort.
Übergang von LLMs zu AI-Assisted Discovery
Generative KI und Large Language Modelle (LLMs) beschränken sich derzeit vorwiegend auf die Ausführung von Routineaufgaben wie z.B. Geschäftsberichte erstellen oder die Wiedergabe bereits bekannter Informationen. Das wirkliche Versprechen der KI aber kann erst eintreten, wenn Maschinen den Prozess der Entdeckung durch das Erfassen, Synthetisieren und Lernen aus Daten nachbilden können („the thinking machine“) – und so in wenigen Tagen ein Spezialisierungsniveau erreichen können, für das bisher Jahrzehnte an Lernaufwand nötig wären. Grundlegende IT-Infrastruktur-Kompromisse haben Anwendungen bisher auch daran gehindert, Datensammlungen aus globalen Infrastrukturen in Echtzeit zu verarbeiten und zu verstehen.
Kommentar MIT-Professor und KI-Forscher Max Tegmark: „Um in dieser Ära der KI und des Deep Learning wirklich etwas bewirken zu können, sind nicht nur viele Daten nötig, sondern auch qualitativ hochwertige Daten, die richtig organisiert sind und zur richtigen Zeit am richtigen Ort zur Verfügung stehen. Solange wir die potenziellen Risiken beherrschen, wird die KI immense Vorteile mit sich bringen und uns dabei helfen, viele der Probleme zu lösen, die die Menschheit bisher vor den Kopf gestoßen haben – von der Heilung von Krankheiten über die Beseitigung der Armut bis hin zur Stabilisierung unseres Klimas. Es ist unglaublich inspirierend, also lassen Sie uns die erstaunlichen Chancen, die diese Ära der KI-gestützten Möglichkeiten bietet, nicht verspielen.“
Data Platform: Zu den Ankündigungsdetails
Um Deep Learning für Daten zu ermöglichen, wurde die VAST Data Platform mit Blick auf das gesamte Datenspektrum natürlicher Daten entwickelt – unstrukturierte und strukturierte Datentypen in Form von Videos, Bildern, freiem Text, Datenströmen und Instrumentendaten. Diese Plattform ermöglicht es, Daten, die aus der ganzen Welt stammen, in Echtzeit mit einem globalen Datenmodell zu verarbeiten. Der Ansatz zielt darauf ab, die Lücke zwischen ereignis- und datengesteuerten Architekturen zu schließen, indem er laut den EntwicklerInnen folgenden Möglichkeiten bietet:
- Zugriff und Verarbeitung von Daten in jedem Private- oder großen Public-Cloud-Rechenzentrum.
- Natürliche Daten verstehen, indem eine abfragbare semantische Schicht in die Daten selbst eingebettet wird.
- Kontinuierliche und rekursive Berechnung von Daten in Echtzeit, die sich mit jeder Interaktion weiterentwickelt.
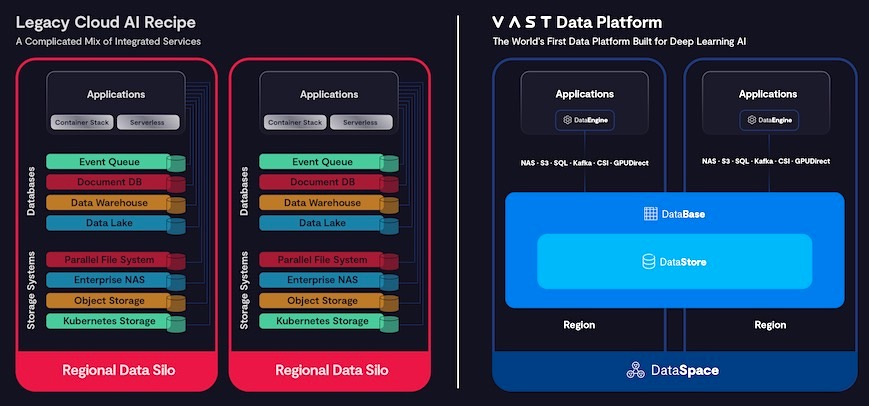
Seit Jahren arbeitet VAST nach eigenen Angaben deshalb bereits an einer Vision – natürliche Daten, umfangreiche Metadaten, Funktionen und Trigger – in den Mittelpunkt seiner Distributed-Systems-Architektur „VAST Disaggregated Shared-Everything (DASE)“ zu stellen. DASE ist die (VAST-) Datengrundlage für Deep Learning, indem es laut Anbieter Kompromisse in Bezug auf Leistung, Kapazität, Skalierung, Einfachheit und Ausfallsicherheit beseitigt, um das Trainieren von Modellen auf allen Daten eines Unternehmens zu ermöglichen. Indem Kunden dem System nun eine Logik hinzufügen können, können Maschinen danach in die Lage versetzt werden, kontinuierlich und rekursiv Daten aus der natürlichen Welt anzureichern und zu verstehen (Hinweis: DASE ist keine shared-nothing Architektur, die mit Mechanismen wie Lock-Management, Caching, Rebuilds, Metadaten etc. arbeitet und deshalb im Umfeld von HPC-Anwendungen je nach Umfang begrenzt skaliert).
Enheitlicher globaler Datenspeicher, Datenbank und KI-Computing-Engine:
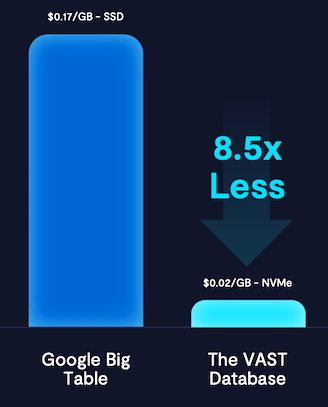
VAST DataStore: Um Daten aus der natürlichen Welt zu erfassen und bereitzustellen, entwickelte VAST die Grundlage seiner Plattform, den VAST DataStore, eine skalierbare Speicherarchitektur für unstrukturierte Daten, um Storage Tiering auszuschließen. Der VAST DataStore ist eine Enterprise Network Attached Storage-Plattform mit Datei- und Objektspeicher-Schnittstellen, die den Anforderungen der aktueller KI-Computing-Architekturen wie NVIDIA DGX SuperPOD AI Supercomputer sowie Big-Data- und HPC-Plattformen gerecht werden soll.
Der DataStore im Exabyte-Maßstab soll mehr Wirtschaftlichkeit in die Flash-Infrastruktur zu bringen – und ist laut VAST auch für Archivierungsanwendungen geeignet. Die Überwindung der Kostenfrage für Flash-Speicher war laut Hersteller entscheidend, um die Grundlage für Deep Learning für Unternehmenskunden zu schaffen, die Modelle auf ihren eigenen Datenbeständen trainieren wollen (bis heute hat der Anbieter nach eigenen Angaben weltweit mehr als zehn Exabyte an Daten mit Kunden wie Booking.com, NASA, Pixar Animation Studios, Zoom Video Communications, Inc. und anderen verwaltet).
VAST DataBase: Um unstrukturierte natürliche Daten zu strukturieren, hat VAST mit der Einführung der VAST DataBase eine semantische Datenbankschicht nativ in das System integriert. Durch die Anwendung der Vereinfachung strukturierter Daten konnten laut Entwickler die Kompromisse zwischen Transaktionen (zur Erfassung und Katalogisierung natürlicher Daten in Echtzeit) und Analysen (zur Analyse und Korrelation von Daten in Echtzeit) gelöst werden. Dazu kamen erstmals Prinzipien zur Anwendung, um die Eigenschaften einer Datenbank, eines Data Warehouse und eines Data Lake in einem einfachen, verteilten und einheitlichen Datenbankmanagement-System zu kombinieren. Die VAST DataBase wurde danach für eine schnelle Datenerfassung und schnelle Abfragen in beliebigem Umfang entwickelt und ist laut Anbieter in der Lage, die Grenzen der Echtzeitanalyse vom Ereignisstrom bis hin zum Archiv zu durchbrechen.
Querverweis: siehe hierzu auch unser Beitrag > VAST Catalog: vereinfachtes Datenmanagement von KI und Big-Data-Analytics Anwendungen
Bildquelle: VAST
VAST DataEngine: Auf der Grundlage von synthetisierten strukturierten und unstrukturierten Daten ermöglicht die VAST Data Platform die Verfeinerung und Anreicherung unstrukturierter Rohdaten in strukturierte, abfragbare Informationen mit zusätzlicher Unterstützung von Funktionen und Triggern. Die VAST DataEngine ist eine globale „Funktionsausführungs-Engine“, die Rechenzentren und Cloud-Regionen zu einem globalen Computing-Framework konsolidiert. Die Engine unterstützt gängige Programmiersprachen wie SQL und Python und führt ein System für Ereignisbenachrichtigungen sowie materialisiertes und reproduzierbares Modelltraining ein, das die Verwaltung von KI-Pipelines erleichtert.
VAST DataSpace: Das letzte Element der VAST Data Platform-Strategie ist der sog. VAST DataSpace, ein globaler Namensraum, der es jedem Standort ermöglicht, Daten von jedem Standort aus mit hoher Leistung zu speichern, abzurufen und zu verarbeiten, während gleichzeitig strenge Konsistenz über jeden Zugriffspunkt hinweg erzwungen wird. Mit dem DataSpace soll die VAST Data Platform in lokalen Rechenzentren und Edge-Umgebungen einsetzbar sein und erweitert den DataSpace-Zugang jetzt auf Public-Cloud-Plattformen wie AWS, Microsoft Azure und Google Cloud.
Diese globale, datendefinierte Computing-Plattform verfolgt einen neuen Ansatz, um unstrukturierte Daten mit strukturierten Daten zu verbinden, indem sie diese Daten in einem zentralen einheitlichen System speichert, verarbeitet und verteilt.
Bildquelle: VAST
Kommentar Renen Hallak, CEO und Mitbegründer von VAST Data (Auszug): „Wir konsolidieren ganze Kategorien von IT-Infrastrukturen, um die nächste Ära groß angelegter Datenberechnungen zu ermöglichen, indem wir die Fähigkeit zur Erstellung und Katalogisierung von Erkenntnissen aus natürlichen Daten auf globaler Ebene bündeln…“ VAST DataStore, die DataBase und der DataSpace sind laut Anbieter im Rahmen der VAST Data Platform ab sofort allgemein verfügbar, die VAST DataEngine soll im Jahr 2024 zur Verfügung stehen.
Kurze Zusammenfassung:
KI- und LLM-Systeme können in Kombination mit den genannten Funktionen der VAST Lösung folgende Leistungsvorteile erzielen (Quelle, Anbieter):
- Direkten Zugang zur natürlichen Welt durch den VAST DataSpace, der die Abhängigkeit von langsamen und ungenauen Übersetzungen beseitigt.
- Die Fähigkeit, riesige Mengen natürlicher, unstrukturierter Daten über den VAST DataStore zugänglich zu speichern.
- Die Intelligenz, unstrukturierte Rohdaten durch die VAST DataEngine in ein Verständnis der ihnen zugrundeliegenden Eigenschaften umzuwandeln.
- Eine Möglichkeit, auf dem gesamten globalen Wissen einer Organisation aufzubauen, es abzufragen und ein besseres Verständnis dafür zu entwickeln – durch die VAST DataBase.
Anwenderkommentar Vijay Parthasarathy, Head of AI/ML bei Zoom: „Wir arbeiten mit VAST zusammen, um unsere KI/ML-Modelle über mehrere unstrukturierte Datensätze von Video-, Audio- und Textdaten hinweg effizient aufzubauen und zu trainieren. Automatisierung ist der Schlüssel, und die VAST Data Platform ermöglicht es uns, über die Fähigkeiten hinauszugehen, die wir bereits aufgebaut haben, um ein reibungsloses globales Kommunikationserlebnis zu bieten.“
Deborah Leff, Chief Revenue Officer bei SQream (Zitatauszug): „Wir sehen aus erster Hand, wie die KI- und Advanced-Analytics-Programme von Unternehmen an die Grenzen dessen stoßen, wofür die CPU-Verarbeitung ausgelegt ist. Unsere Zusammenarbeit mit VAST Data ist ein wichtiger Meilenstein in der Welt der künstlichen Intelligenz und Analytik. Unsere kombinierten Lösungen ermöglichen es den Kunden, die Grenzen der Rechenleistung zu durchbrechen, um massive Datensätze mit extrem hoher Geschwindigkeit zu analysieren."
(1) Quelle / externer Link > Jeff Denworth Blog: The Grand Unification Theory of AI Infrastructure
Laut IDC Worldwide AI Spending Guide, Feb (2023 V1) sollen die weltweiten Ausgaben für KI-zentrische Systeme „weiterhin mit zweistelligen Raten wachsen und erreichen eine fünfjährige (2021-2026) CAGR von 27 Prozent und werden bis 2026 308 Milliarden US-Dollar übersteigen“ (Ritu Jyoti, Group Vice President, AI and Automation Research Practice bei IDC).
Weitere Querverweis:
Unser Blogpost > Parallele scale-out Filesysteme in Kombination mit Object Storage für KI-Anwendungen
Unser Beitrag > KIT KI-Projektausschreibung: Kostenfreier Zugriff auf KI-Infrastruktur und Forschungskompetenz
Unser Beitrag mit Podcast > HPE Alletra Storage MP Ankündigung: Speicher-Architektur und Dienste für Block- und File