Starnberg, 13. Juni 2023 - Neue Applikationen können ihr volles Potenzial nur dann entwickeln, wenn die geeignete IT-Infrastruktur zur Verfügung steht; ein Blogpost…
Zum Blogpost (Lesezeit: ca. 8 min.): Künstliche Intelligenz, High-Performance-Computing, In-Memory-Datenbanken, hybride Cloud-Deployments, IoT und Edge Computing… zunehmend datenzentrierte Anwendungen stellen immer höhere Anforderungen an die Speicherumgebung. Angesichts der Zunahme von Kapazitäten mit unterschiedlichen Datenformaten und I/O-Workload-Profilen ist der Bedarf an leistungsfähigen Lösungen so groß wie nie zuvor. Auf welche Randbedingungen und Lösungsbereiche in diesem Zusammenhang mit dem Schwerpunkt auf KI geachtet werden soll, ist im folgenden Beitrag kurz zusammengefasst.
Das Spannungsfeld: Storage und KI, oder „der Schnittpunkt zwischen künstlicher Intelligenz und modernen Anwendungen sind die Daten. Infrastruktur-Engpässe liegen potentiell auf der Server- und der Speicherebene.“
Auch wenn sich die Applikationsentwicklung derzeit mit Hilfe von Cloud-Ressourcen sehr dynamisch entwickelt, fehlt in-House oft eine wichtige Vorbedingung. Die Rede ist von Datenklassifizierung, um überhaupt brauchbare Basisdaten für KI-Projekte zu liefern. Und es gibt eine weitere Herausforderung: oft wird immer noch bei Speichertechnologien eingespart, weil aus Sicht der Firmenleitung nicht strategisch, oder auch weil spezifisches Know-how sowie Ressourcen wie Fachkräfte fehlen. Dementgegen steht jedoch die geforderte erfolgreiche und rasche Umsetzung von KI-Initiativen, die jedoch nur über eine konsequente Modernisierung der IT-Infrastruktur und des Storage (Hardware / Software) geleistet werden kann. Zumal Themen wie KI und die zeitnahe Entwicklung neuer Business-Apps potentiell zu einer schlecht vorhersehbaren Auslastung der IT-Infrastruktur führen kann, was wiederum dann andere Bereiche negativ beinflusst.
Und die Datenkapazitäten werden sich weiter vergrößern. Für Unternehmen sind diese Daten aber nur dann wertvoll, wenn sie in einen sinnvollen betrieblichen Zusammenhang gestellt werden, d.h. neue Technologien können ihr volles Potenzial erst dann entwickeln, wenn man in der Lage ist, die relevanten Unternehmensbereiche mit den Möglichkeiten der künstlichen Intelligenz wertschöpfend zu verknüpfen. Einer möglichst optimalen Datenverwaltung und Speicherung kommt deshalb eine zentrale Bedeutung zu.
Daneben gewinnt die Weiterentwicklung von Rechenzentrum-Infrastrukturen auch unter dem Aspekt der Energieeffizienz an Bedeutung. Mit high-density-Architekturen steigen auch die Energiekosten, so dass dieser Faktor nicht vernachlässigt werden darf. Alleine die Kosten und Ausgaben für Power & Cooling haben sich laut IDC über die letzten 10 Jahre im RZ um mehr als den Faktor 8 erhöht.
Skalierbare E-/A-Leistung als Differenzierungsfaktor
Leistungsabhängige Anwendungen mit massiven Datensätzen benötigen skalierbare, konstant hohe I/O-Leistungswerte (IOPS, GB/s) bei möglichst geringer Latenz, und das zu vertretbaren Kosten.
Hochparallele I/O-Architekturen bei Server und Storage, NVMeoF im Verbund mit NAND Flash (künftig für Cold Data und Archivbereiche auch PLC = Penta-level-Cell) und Storage Class Memory (SCM) sind die Basis für moderne Speicherplattformen. Gesteuert wird die Hardware über Software-definierte Systeme auf Server- bzw. Appliance-Ebene. Scale-out distributed Filesystem-Lösungen z.B. adressieren das Wachstum im unstrukturierten File-Storage-Umfeld, welches Planungsseitig im Zusammenhang mit KI-Plattformen mit Object- und ggf. Blockstorage zu berücksichtigen ist. Beispiel: moderne Hochleistungs-Filesysteme integrieren NVMe-basierten Flash-Speicher auf der I/O-Leistungsebene mit GPU-Servern, Objektspeicher und Interconnect-Fabrics mit niedriger Latenz innerhalb einer NVMe-over-Fabrics-Architektur. Querverweis: Unser Beitrag > https://storageconsortium.de/content/content/parallele-scale-out-filesysteme-kombination-mit-object-storage-f%C3%BCr-ki-anwendungen
Auf der Server-/Host-Schnittstellenseite ist aus Standardisierungssicht Compute Express Link (CXL) eine leistungsstarke und wirtschaftliche Basis (OPEX) für die genannten Anforderungen. CXL wurde als Standard in 2019 veröffentlicht und entwickelt sich kontinuierlich weiter (v.3.0 in Vorbereitung). CXL als Weiterführung des Gen-Z-Standard und offener Industriestandard für Verbindungen mit hoher Bandbreite sowie niedriger Latenz zwischen Host-Prozessor und Geräten wie Beschleunigern, Memory Buffers und intelligenten E/A-Devices konzipiert. Querverweis: Unser Beitrag > https://storageconsortium.de/content/content/storage-f%C3%BCr-ki-welche-speichertechnologien-sind-daf%C3%BCr-geeignet
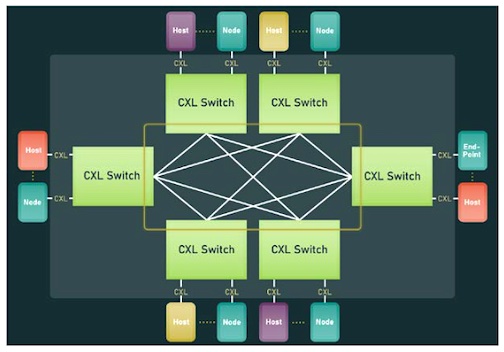
Abb.: CXL Fabric Non-Tree Topology (Referenz / Quelle: CXL, Compute Express Link 3.0. Dr. Debendra Das Sharma, Intel Fellow and Director, I/O Technology and Standards, and
Ishwar Agarwal, Principal Hardware Engineer, Microsoft Azure Hardware Architecture
Co-Chairs, CXL BoD Technical Task Force, CXL Consortium).
Link > https://www.computeexpresslink.org/
Anmerkung zur Abbildung: Mit CXL 3.0 werden zum ersten Mal Fabric-Funktionen eingeführt, die über die traditionelle tree-basierte Architektur von PCIe und früheren CXL-Generationen hinausgeht. Die Abbildung zeigt beispielhaft eine nicht baumbasierte Topologie dieser neuen CXL-Fabric.
Latenzen und der Durchsatz von Speichersystemen wirken sich direkt auf die Leistung eines KI-Gesamtsystems aus und ML-Implementierungen sind stark auf GPU-basierte parallele Berechnungen angewiesen. Sie benötigen einen schnelle Speicher, je nach Implementierung mit DRAM, Persistent Memory und NAND Flash. Gerade ältere Storage-Systeme, die HDDs mit seriellen Schnittstellen wie SATA und SAS kombinieren, sind in Bezug auf diese Workload-Profile nicht zukunftssicher und hierfür nicht geeignet.
Anwendungsseitig ist bei Deep Learning der Data Ingest zwar ein relativ einfaches Streaming an sequentiellen Schreibvorgängen; die weiteren Prozesse bestehen dann vielfach aus kleinen „random“ Lese-Operationen. KI wird Storageseitig deshalb auch zur Mustererkennung beim Datenzugriff selbst eingesetzt. Daten werden mit dieser Methode proaktiv in den Cache verlagert, noch bevor sie vom User angefasst werden. Für eine weitere systemnahe Speicherung der erkalteten Daten (nicht mehr aktiv) können diese auf Basis definierter Richtlinien dann automatisiert in den Objekt-Storage-Bereich einer Cloud verschoben werden.
Bekanntlich müssen GPUs immer genügend Daten zur Verfügung haben, denn unausgelastete GPUs verlangsamen den gesamten Prozess und sind teuer. Es ist aus Sicht der KI-Anwendung wichtig, dazu eine entsprechend hohe "Ingest"-Bandbreite für zufällige Zugriffsmuster von kleinen bis großen Files bereitzustellen. Bei kleineren Datensätzen ist das weniger ein Thema, weil neuronale Netzwerke innerhalb jeder Trainingseinheit auf die gleichen Daten zugreifen; diese können dann lokal auf Flash oder RAM zwischengespeichert werden.
Bei komplexen Deep Learning (DL) Algorithmen bedeutet ein langsamer Speicher aber immer eine langsamere maschinelle Lernleistung. Das Deep Neural Network ist ein Abbild eines massiv parallelen vernetzten Modells und dementsprechend leistungsfähig. GPUs sind massiv parallele Prozessoren, bei denen jeder einzelne aus Tausenden von lose gekoppelten Rechenkernen besteht, um eine entsprechend höhere Leistung als Standard CPUs zu erzielen.
Flash SSD Storage Limits
Zufällige (random) Leseleistung bei geringer Warteschlangen-Tiefe ist für NAND Flash SSDs aus Performance-Sicht nicht unproblematisch. Persistent Memory Implementierungen auf Basis von Storage Class Memory (SCM) für high-performance KI-Infrastrukturen hingegen können eine 5-bis 10-fache Leistung gegenüber SSDs bei einer Random Read Queue Depth (QD) von 1-4 liefern.
Serverseitig sollte berücksichtigt werden, dass ältere Hardware-Systeme nicht in der Lage sind, eine moderne Befehlssatzarchitektur und Multithreading zu unterstützen, wie es für KI notwendig sein kann (s.a. VNNI, Vector Neural Network Instructions für die maschinelle Verarbeitung von Bild- und Audiodateien mittels künstlichen neuronalen Netzen / CNNs). Neuere hochleistungsfähige Prozessoren mit hardwareseitigem Multithreading können auf jedem Prozessorkern parallel mehrere Programme oder Programmteile gleichzeitig ausführen. Link > https://en.wikichip.org/wiki/x86/avx512_vnni
Auch FPGAs (Field Programmable Gate Arrays) werden aus Kosten- und Leistungsgesichtspunkten für KI-Workloads attraktiv gegenüber klassischen GPU- und CPU-Implementierungen. Speziell der Energieverbrauch bei zunehmend komplexen KI-Algorithmen kann damit besser gelöst werden. Mit schnellen lokalen FPGA-on Chip Speichern lassen sich zudem große Datenmengen in Echtzeit verarbeiten. Aufgrund der hohen Speicherbandbreite von FPGA-Konfigurationen kann je nach Implementierung aber eine hochleistungsfähige externe Speicherlösung zur Weiterverarbeitung nötig sein. Zu beachten ist auch, dass programmierbare Hardwarebeschleuniger wie FPGAs von älteren Anwendungen kaum unterstützt werden.
Weitere I/O-Performance-Parameter
Wie mehrfach in früheren Beiträgen erwähnt, skaliert ein einfacher auf SSDs aufgebauter Storage mit SAS / SATA Interface bei komplexeren KI-Anforderungen mit schnell wachsenden massiven Datensätzen nicht linear (Betrifft Latency, OPEX, CAPEX). Die Lösung besteht deshalb in der Bereitstellung von hochparallelen I/O-Architekturen wie NVMe nebst Hardware im Verbund mit einer optimierten Speicherverwaltungs-Software (z.B. Scale-out Filesystem mit NFS-Optimierungen). NVMeoF und RDMA über 100 GBE (bestimmte HPC-Anwendungen auch mit InfiniBand) sind Hardware- und Protokollseitig für den Storage- und Applikationen derzeit Protokolle der Wahl für Low-latency, high Performance I/Os. Hohe Random-I/O-Leseleistung bei geringer Warteschlangentiefe (queue depth, QD) ist Performance-seitig ein wichtiges Kriterium (random reads stellen generell aber rund 75% aller Transaktionen dar und sind eine relevante Kennzahl für die Subsystem-Performance).
Die Kombination aus QLC-NAND Flash (Kapazität, Preis) und Storage Class Memory (Leistung) kann eine leistungsfähige Basis zum Aufbau skalierbarer Storage-Plattformen für KI-Infrastrukturen darstellen. QLC auch deshalb, weil bei KI-Anwendungen Read-to-Write I/O-Relationen von bis zu 5000:1 möglich sind (Deep Learning), während wir bei klassischen RZ-Anwendungen von 4:1 sprechen. Die Haltbarkeit der NAND-Zellen (wear-out) ist damit deutlich erhöht. QLC ist dann zuverlässiger als ein Subsystem mit SATA-HDDs, wenn eben deutlich mehr gelesen als geschrieben wird. Und auf Grund der hohen Read-Performance ist ein Flash Drive über 400 mal schneller als das drehende Laufwerk. Anders verhält es sich bei inaktiven Daten, bei denen die HDD weiterhin eine Rolle spielt.
Zusätzliche Storage-Anforderungen betreffen das immer stärkere Datenwachstum im Edge. Daten können von einem bestimmten Sensor oder einer Gruppe von Geräten übertragen werden und zudem ereignisgesteuert sein, d.h. weniger vorhersehbare Muster bei der Datenübertragung sind dann auch dort zu erwarten; das Volumen und die I/O-Muster können stärker zufällig (random) sein. Edge-Storage-Dienste sind dort per se überall zu finden, im Rechenzentrum, in der Cloud oder in der Nähe der Datenquelle. Das bedeutet eine weitere Herausforderung für die Speicherverwaltung und ein Grund mehr für Software Definierte IT-Architekturen anstelle vieler verteilter Silos, die zunehmend kostenintensiver und schwerer zu beherrschen sind.
Querverweise zum Thema:
Unser Beitrag > Energieverbrauch der Rechenzentrumsbranche in 2023: Mehr Effizienz und Alternativen gefordert
Unser Beitrag > Micron 9400 NVMe SSD: Neue Hochleistungs-Drives für mixed Workloads in Rechenzentren
Unser Beitrag > Technologietrends 2023 der Western Digital Corporation mit Ausblick: Daten im Mittelpunkt