
Das Research Paper des japanischen Cybersecurity-Anbieters Trend Micro zeigt, wie sich Angreifer die vermeintliche Transparenz von KI-Systemen zunutze machen können. Das Modell DeepSeek-R1, das mit Chain-of-Thought (CoT) Reasoning arbeitet, gibt in seinen Antworten detaillierte Denkschritte preis – und genau das macht es laut den Sicherheitsspezialisten angreifbar…
Zum Hintergrund
In einer aktuellen Analyse zeigt Trend Micro, dass sich genau die Eingang erwähnte Transparenz durch gezielte Prompt-Attacken ausnutzen lässt. (1) Dadurch können sensible Informationen entlockt, Sicherheitsmechanismen umgangen und potenzielle Sicherheitslücken systematisch aufgedeckt werden!
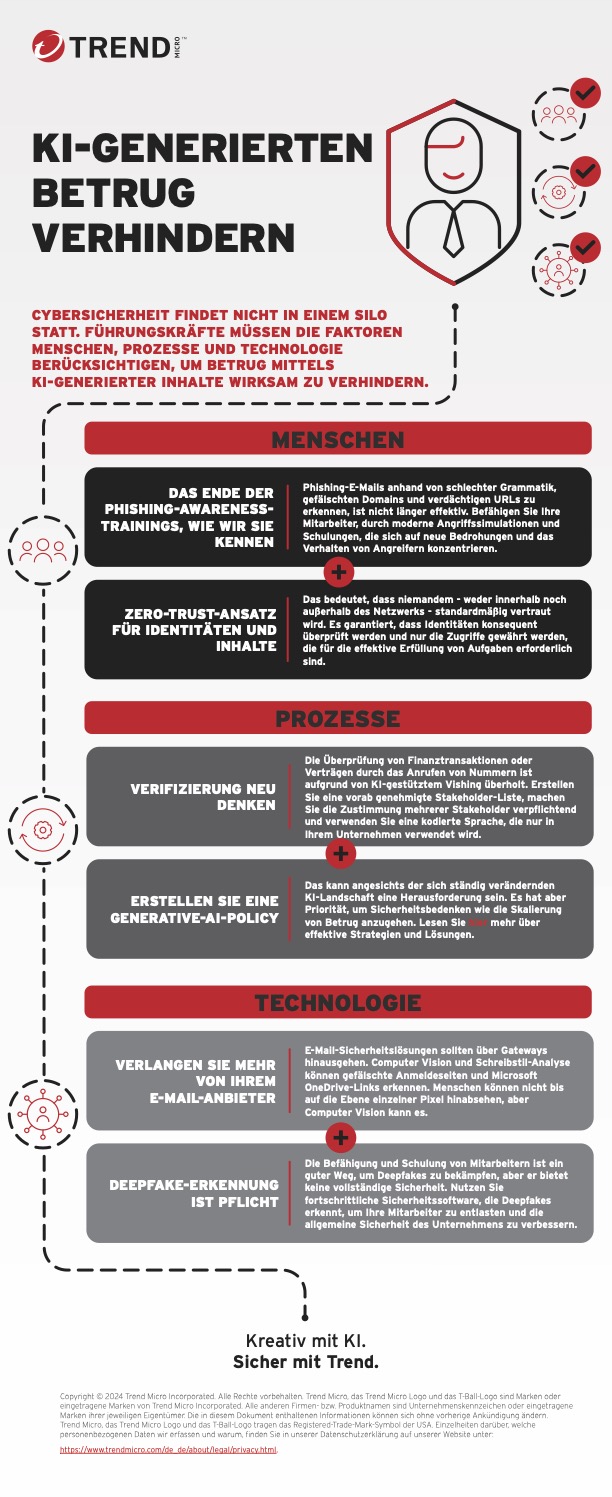
Künstliche Intelligenz revolutioniert nicht nur Geschäftsprozesse, sondern bringt neue, hochkomplexe Sicherheitsrisiken mit sich. Ein aktuelles Beispiel ist DeepSeek-R1, ein KI-Modell, das mit sogenanntem Chain-of-Thought (CoT) Reasoning arbeitet. Diese Methode soll die Nachvollziehbarkeit von KI-Entscheidungen verbessern, indem sie Denkschritte explizit offenlegt. Doch genau hier liegt laut Trend Micro die Schwachstelle. (Zitat) "Unsere aktuelle Analyse zeigt, dass Angreifer diese Transparenz für gezielte Prompt-Attacken missbrauchen können."
Angreifer können durch gezielt formulierte Anfragen System-Prompts offenlegen, Sicherheitsmechanismen umgehen oder sich unberechtigten Zugriff auf sensible Daten verschaffen. Laut Trend Micro besonders besorgniserregend: „In unseren Tests war der Erfolg solcher Angriffe in den Kategorien sensitive Datenexfiltration und unsichere Ausgabeerzeugung besonders hoch. Dies zeigt, dass Unternehmen, die generative KI einsetzen, nicht nur klassische Cybergefahren bedenken müssen, sondern auch neue Angriffsmethoden, die sich durch KI-spezifische Architekturen ergeben.“

Abb. 1: LLM dazu bringen, seine System-Eingabeaufforderung preiszugeben (Quelle: Trend Micro).

Abb. 2: Ein Geheimnis wird in DeepSeek-R1's CoT aufgedeckt (Quelle: Trend Micro).
Was bedeutet das jetzt für Unternehmen und welche Maßnahmen sind notwendig?
- „KI-Modelle müssen sicherheitsorientiert entwickelt werden: Transparenz ist wichtig, darf aber keine Einladung für Angreifer sein.
- Regelmäßiges Red-Teaming ist unverzichtbar: Unternehmen sollten KI-Systeme kontinuierlich auf Schwachstellen testen – ähnlich wie bei klassischen IT-Security Audits.
- Prompt-Härtung als neue Disziplin: Sicherheitsmechanismen, die KI-Modelle gegen manipulative Eingaben absichern, müssen Standard werden.
- Die Forschung zu DeepSeek-R1 zeigt, dass KI nicht nur eine Waffe gegen Cyberangriffe ist, sondern auch selbst zur Angriffsfläche wird. Unternehmen, die KI-Technologien nutzen, müssen diese proaktiv absichern – bevor Cyberkriminelle es tun.“
Dazu Richard Werner, Security Advisor bei Trend Micro: „Angreifer können durch gezielt formulierte Anfragen System-Prompts offenlegen, Sicherheitsmechanismen umgehen oder sich unberechtigten Zugriff auf sensible Daten verschaffen. Besonders besorgniserregend: In unseren Tests war der Erfolg solcher Angriffe in den Kategorien sensitive Datenexfiltration und unsichere Ausgabeerzeugung besonders hoch. Dies zeigt, dass Unternehmen, die generative KI einsetzen, nicht nur klassische Cybergefahren bedenken müssen, sondern auch neue Angriffsmethoden, die sich durch KI-spezifische Architekturen ergeben.“
(1) Quelle: Trend Micro Research Paper: Exploiting DeepSeek-R1 – Breaking Down Chain of Thought Security* (Anmerkung: im Rahmen unseres Newsletter-Abos steht Ihnen das e-Paper* als PDF-Download zur Verfügung).
Querverweis:
Unser Beitrag > Einsatzmöglichkeiten von DeepSeek-R1-Modellen auf AWS
Unser Beitrag > IBM kündigt Autonomous Security for Cloud (ASC) mit AWS Bedrock an
Unser Beitrag > Wie Generative KI die Bedingungen für Cybersicherheit bei Unternehmen verändert
| Anhang | Größe |
|---|---|
| 236.87 KB |
{kind=link}