
NVIDIA zeigt neue BlueField-4 STX Storage Referenzarchitektur. Beteiligung von DDN, Cloudian, Dell Technologies, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, VAST Data und WEKA…
Hintergrund
GenAI und KI-Fabriken benötigen eine neue Art der Datenspeicherung
Die jährlich stattfindende KI-Konferenz von NVIDIA vom 16. bis 19. März 2026 San Jose (CA) ist für Storage im Kontext von NVIDIA aus verschiedenen Gründen von Bedeutung und im Gegensatz zur GTC 2025 (jedenfalls aus Storagesicht) deutlich umfangreicher ausgefallen. Warum das so ist und welche Neuerung dort gerade vorgestellt werden, finden Sie hier in einer kompakten Übersicht (Achtung: Umfangreich! Lesezeit ca. 15 min).
Traditionelle Rechenzentren bieten Speicher mit hoher Kapazität, Verfügbarkeit und Leistung für allgemeine kommerzielle Anwendungen, jedoch nicht im geforderten Leistungsumfang für KI-Fabriken und der dort nötigen (Realtime-)Interaktion mit AI-Agents. Agenten-basierte KI verlangen einen konstanten Echtzeit-Datenzugriff sowie ein kontextbezogenes „Arbeitsgedächtnis“, um Konversationen und Aufgaben nicht nur schnell, sondern auch kohärent zu gestalten. Bei einem zunehmend komplexen Kontext verlangsamen herkömmliche Speicherarchitekturen- und Datenpfade jedoch die KI-Inferenz; damit verringert sich die GPU-Auslastung.
I) Speicherbezogene Ankündigung von NVIDIA
NVIDIA STX soll es Unternehmen und Speicheranbietern ermöglichen, eine Infrastruktur aufzubauen, die Daten möglichst direkt und in großem Maßstab zugänglich hält, sodass KI-Fabriken einen höheren Durchsatz sowie bessere Reaktionsfähigkeit bei Inferenz, Training und Analyse liefern.
Als erste Implementierung im Rack-Maßstab wurde die neue NVIDIA CMX™-Kontext-Speicherplattform gezeigt, die GPU-Speicher um eine Kontext-Ebene für skalierbare Inferenz- und agentische Systeme erweitert – laut Entwickler soll sie im Vergleich zu bisherigen Storage-Implementierungen bis zu 5-mal mehr Tokens pro Sekunde bereitstellen.
STX wird durch die NVIDIA Vera Rubin-Plattform beschleunigt und nutzt den neuen, speicheroptimierten NVIDIA BlueField-4-Prozessor, der NVIDIA Vera-CPUs mit NVIDIA ConnectX®-9 SuperNIC kombiniert, zusammen mit NVIDIA Spectrum-X™-Ethernet-Netzwerktechnologie, NVIDIA DOCA™ und NVIDIA AI Enterprise-Software.
Storage-Next von NVIDIA ist in diesem Zusammenhang ein Speicherkonzept, das Leistung und Wirtschaftlichkeit für KI-Infrastrukturen weiter erhöhen soll. Dahinter verbirgt sich Flash Storage mit HBM, der sich performance-seitig wie Arbeitsspeicher verhält. Damit soll die Latenz verringert, IOPS gesteigert und eine besser Wirtschaftlichkeit erreicht werden, die mit steigenden GPU-Workloads entsprechend skaliert.
Zu den Speicheranbietern, die gemeinsam die nächste Generation der KI-Infrastruktur auf Basis von NVIDIA STX entwickeln, gehören laut NVIDIA aktuell die Firmen Cloudian, DDN, Dell Technologies, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, VAST Data und WEKA (laut NVIDIA sollen STX-basierte Plattformen in der zweiten Jahreshälfte 2026 dann bei Partnern erhältlich sein).
Zu den Fertigungspartnern, die STX-basierte Systeme bauen, gehören AIC, Supermicro und Quanta Cloud Technology (QCT).
KI-Labors und Cloud-Dienstleister, die den Einsatz von STX für den Kontext-Speicher planen, sind CoreWeave, Crusoe, IREN, Lambda, Mistral AI, Nebius, OCI und Vultr.

Abb.: NVIDIA BlueField-4 STX Storage (Bildquelle: NVIDIA).
Externer Link > https://www.nvidia.com/de-de/data-center/ai-storage/
Mit der Integration von beschleunigtem Computing und Netzwerktechnik in die Datenspeicher-Fabric und die Optimierung des Software-Stacks sieht es das neue Speicherkonzept vor, Storage-Partner von NVIDIA direkt dabei zu unterstützen, Hyperscale-Effizienz in den Bereichen Inferenz und Training zu erreichen. Das Unternehmen stellt hierzu drei KI-Datenspeicherarchitekturen bereit (Quelle, Anbieter):
- NVIDIA STX: Modulare Referenzarchitektur für KI-Datenspeicher-Workloads
- Kontext-Datenspeicher NVIDIA CMX: KI-native Datenspeicherebene erweitert GPU-Kontext-Speicher für Inferenz mit langem Kontext
-
NVIDIA KI-Datenplattform: Anpassbares Referenzdesign, das NVIDIA-beschleunigtes Computing in Unternehmens-Datenspeicher integriert.
II) Verschiedene Speicheranbieter-Ankündigungen im Rahmen der NVIDIA GTC 2026 (Auszug, kein Anspruch auf Vollständigkeit):
1. DDN
"DDN stattet den NVIDIA DGX SuperPOD für generative KI mit 12 Petabyte hochleistungsfähigem Flash-Speicher aus. Erfolgreiche Implementierung des DDN EXAScaler® AI-Speichers (A³I®) in NVIDIA Eos, einem TOP-10-Supercomputer, auf Basis des NVIDIA DGX SuperPOD. (1)
Durch die Integration von 576 NVIDIA DGX H100-Systemen, NVIDIA Quantum-2 InfiniBand-Netzwerktechnologie und NVIDIA AI Enterprise-Software in die DGX SuperPOD-Referenzarchitektur hat DDN nach vorliegenden Angaben eine performante und äußerst energieeffiziente Speicherlösung mit 48 DDN A³I-Appliances in weniger als drei Racks und einem Stromverbrauch von 100 kW entwickelt.
Im Ergebnis stehen 12 Petabyte DDN-Speicher, der laut Anbieter eine Datenübertragungsrate von vier Terabyte pro Sekunde liefert und damit 18,4 Exaflops an FP8-NVIDIA-KI-Leistung ermöglichen soll. NVIDIA Eos unterstützt laut Entwickler die größten KI-Workloads, große Sprachmodelle, Recommender-Systeme und Simulationen.
Abb.: DDN EXAScaler Product Family (Bildquelle: DDN).
(1) Quelle / externer Link > https://www.ddn.com/
2. HPE Storage
HPE Alletra Storage MP X10000 NVIDIA-zertifizierte objektbasierte Speicherplattform auf Foundation-Ebene- Verbesserte KI-Datenpipelines durch erweiterte NVIDIA-Integration
Die Zertifizierung bedeutet, dass NVIDIA die Leistung für Lasten von bis zu 128 GPUs im Benchmark validierte, Funktionstests für Verfügbarkeit und Zuverlässigkeit auf Unternehmensniveau durchführte und dass die Speicherschicht Daten effizient an beschleunigte Rechenressourcen weiterleitet, um ein schnelleres Modelltraining, Inferenz mit geringerer Latenz und eine bessere Gesamtauslastung zu ermöglichen.
Um die Zusammenarbeit mit NVIDIA weiter auszubauen, plant HPE die neue NVIDIA STX-Rack-Scale-Referenzarchitektur zu unterstützen, um neue KI-Speicherlösungen zu entwickeln, die auf NVIDIA Vera Rubin, BlueField-4, Spectrum-X-Netzwerktechnologie, Connect-X-NICs und NVIDIA-KI-Software basieren.
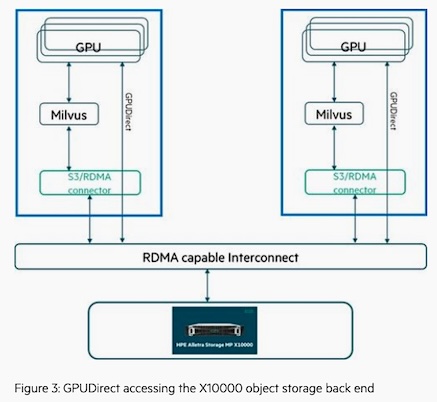
Abb.: Figure 3: GPUDirect accessing the X10000 object storage back end (Bildquelle: HPE, Storage).
Quelle / externer link > https://www.hpe.com/us/en/events/nvidia-gtc.html
Auf Basis von HPE Alletra Storage MP X10000, mit NVIDIA cuVS für GPU-beschleunigte Vektorindizierung und NVIDIA cuObject für beschleunigte Speicher-E/A ausgestattet, lässt sich die Indexerstellung, die früher auf CPU-Clustern Stunden in Anspruch nahm, laut Hersteller nun in wenigen Minuten abschließen.
Die HPE-Experimente haben laut Hersteller eine 17-fache Verbesserung der Indexerstellungszeit und eine 8-fache Verbesserung des gesamten End-to-End-Pipeline-Transports bei Verwendung einer NVIDIA H100 und beschleunigtem Remote Direct Memory Access (RDMA) ergeben. Die Untersuchung bewertet die End-to-End-Leistung der Vektorindizierung unter Verwendung von HPE Alletra Storage MP X10000-Objektspeicher, Simple Storage Service (S3, entwickelt von Amazon) über RDMA, Milvus 2.6 und einer einzelnen NVIDIA H100-GPU. Die Ergebnisse zeigen, wie GPU-Beschleunigung und hochleistungsfähiger Objektspeicher als integrierte Lösung zusammenwirken und es ermöglichen, Vektorindizierungs-Workloads im Terabyte-Bereich in weniger als einer Stunde abzuschließen.
Ferner stellte HPE AI Grid vor, eine End-to-End-Lösung, die auf der NVIDIA-Referenzarchitektur basiert und AI-Fabriken sowie verteilte Inferenzcluster über regionale Standorte und Standorte am äußersten Rand des Netzwerks hinweg sicher miteinander verbinden soll. Das HPE AI Grid orientiert sich an der NVIDIA AI Grid-Referenzarchitektur, um Serviceprovidern einen einheitlichen Hardware- und Software-Stack bereitzustellen.
HPE AI Grid umfasst: Telekommunikationstaugliches Multicloud-Routing und kohärente Optik von HPE Juniper für vorhersehbare Langstrecken- und Metro-Konnektivität; Cloud-native und mandantenfähige Sicherheit; Firewalls; WAN-Automatisierung; sowie Orchestrierung für Zero-Touch-Bereitstellung und Lebenszyklus-Betrieb, HPE ProLiant Compute Edge- und Rack-Server mit NVIDIA-beschleunigter Rechenleistung, einschließlich NVIDIA RTX PRO 6000 Blackwell-GPUs sowie NVIDIA BlueField-DPUs, Spectrum-X-Ethernet-Switches, Connect-X-SuperNICs und KI-Blueprints für schnelle KI-Inferenz.
3. WEKA
WEKA hat die allgemeine Verfügbarkeit seiner NeuralMesh™ AI Data Platform (AIDP) bekannt gegeben, die eine kompatible, hochleistungsfähige Infrastruktur für Unternehmen bietet, die für AI Factory-Implementierungen optimiert ist. Die Lösung basiert auf dem Referenzdesign der NVIDIA AI Data Platform und ist ein End-to-End-System, das die Bereitstellung von KI-fähigen Daten für AI Factories beschleunigt. Das Ergebnis: Die Zeitspanne für KI-Projekte verkürzt sich von Monaten auf Minuten, sodass Unternehmen in der Lage sind, KI-Anwendungen im Produktionsmaßstab unter Verwendung der besten Technologien in ihrem gesamten Ökosystem bereitzustellen.
NeuralMesh AIDP ermöglicht es Unternehmen und KI-Cloud-Anbietern, KI-Vorgänge von der Abfrage bis zur Inferenz auf einer einzigen, sofort einsatzbereiten Plattform zu vereinheitlichen. Mit vorintegrierten Hardware- und Software-Optionen von NVIDIA (einschließlich NVIDIA RTX 6000 PRO Server Edition GPUs und der neu angekündigten NVIDIA RTX 4500 PRO Server Edition GPUs) sowie Red Hat, Spectro Cloud und Supermicro können Unternehmen monatelange KI-Integrationsarbeit vermeiden.
Die Plattform bietet eine vereinfachte Lösung, die es Teams ermöglicht, sich auf den Informations-Output zu konzentrieren, anstatt die zugrunde liegende Infrastruktur zu verwalten. Die Lösung bietet laut WEKA gebrauchsfertige Pipelines für ein breites Spektrum von Geschäftsanwendungen, die in verschiedenen Branchen eingesetzt werden können: Semantic Search, Video Search & Summarization (VSS), AlphaFold für die Arzneimittelentdeckung, AIQ/Agentic RAG und vieles mehr.
Abb.: WEKA NeuralMesh (Bildquelle: WEKA).
Externer Link > https://www.weka.io/partners/nvidia/
4. VAST
VAST Data stellt „Foundation Stacks“ vor, um die Einführung von NVIDIA Blueprints in Unternehmen zu beschleunigen.
VAST Foundation Stacks ist eine neue Open-Source-Bibliothek, die NVIDIA AI Blueprints ergänzt und zu produktionsreifen Pipeline-Implementierungen erweitert, die nativ auf dem VAST AI-Betriebssystem laufen.
NVIDIA AI Blueprints bieten Entwicklern einen grundlegenden Ausgangspunkt für die Erstellung fortschrittlicher KI-Anwendungen und intelligenter Agenten. Dabei nutzen sie die NVIDIA AI Enterprise-Software, um domänenspezifische KI-Workflows mit minimalem Integrationsaufwand schnell zu prototypisieren, anzupassen und bereitzustellen.
VAST Foundation Stacks erweitern diese Blueprints zu produktionsreifen Vorlagen und ermöglichen es Unternehmen, NVIDIA-basierte Pipelines nativ auf dem VAST-KI-Betriebssystem bereitzustellen und zu betreiben. Entwickler können sich nun auf die Geschäftslogik konzentrieren, die KI mit ihrer Umgebung verbindet, anstatt die zugrunde liegenden Infrastruktur- und Plattformschichten aufzubauen, die zur Unterstützung erforderlich sind…
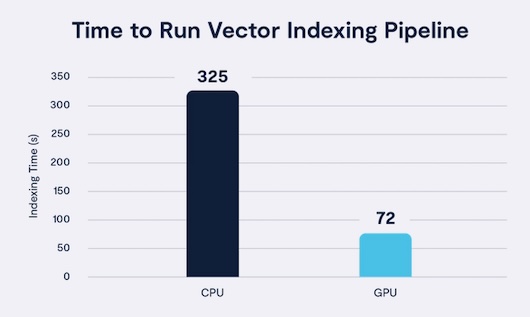
Abb: Comparison of indexing time with CPU-only vs. GPU-accelerated systems (Bildquelle: VAST). Externer link > https://www.vastdata.com/blog/powering-enterprise-ai-high-velocity-vector-search-sql
VAST Data mit Supermicro: Auf der NVIDIA GTC 2026 präsentiert Supermicro die bevorstehende Veröffentlichung der „Supermicro Unified AI Data Platform“ mit VAST, die die „Data Center Building Block Solutions“ zu einer einheitlichen Architektur für Unternehmens-KI erweitert. Die Plattform basiert auf einer modularen Supermicro-Infrastruktur und wird vom VAST AI OS angetrieben.
Supermicro EBox bietet eine VAST-zertifizierte All-Flash-Grundlage für einheitliche Datei-, Objekt-, Block- und Datenbankdienste, während der Supermicro CNode-X GPU-beschleunigte Dienste näher an die Daten heranbringt – für Vektorsuche, SQL, Abruf und Agentic-Workflows.
5. IBM Corp.
IBM kündigt Fortschritte in den Bereichen GPU-native Datenanalyse, Extraktion unstrukturierter Daten, On-Premise- und Cloud-Infrastruktur, Beschleunigung der Entscheidungsfindung in der globalen Lieferkette von Nestlé sowie Beratung zur großflächigen Einführung von Unternehmens-KI an.
Beschleunigung der strukturierten Datenanalyse durch GPU-natives Computing: IBM und NVIDIA arbeiten gemeinsam an einer Open-Source-Integration, um die Leistung zu steigern und die Kosten zu senken, die Unternehmen bei der Gewinnung von Erkenntnissen aus ihren riesigen Datensätzen entstehen. Die SQL-Engine Presto von IBM watsonx.data wird durch NVIDIA cuDF beschleunigt, um eine schnellere Abfrageausführung bei großen Datensätzen zu ermöglichen.
Den meisten Unternehmen mangelt es nicht an Daten... Oft sind sie nur nicht in der Lage, darauf zuzugreifen und sie zu nutzen. SharePoint-Websites, CMS-Systeme, Lieferantenrecherchen, KMU-Wissen: Die Informationen sind vorhanden, aber sie sind in unstrukturierten, multimodalen Formaten gefangen, die schwer zu extrahieren, zu standardisieren und bei Entscheidungsgeschwindigkeit als vertrauenswürdig einzustufen sind.
IBM und NVIDIA gehen dieses Problem mit Docling von IBM und den offenen Modellen von NVIDIA Nemotron an – einer Kombination, die darauf ausgelegt ist, intelligente Dokumentenextraktion im Unternehmensmaßstab zu ermöglichen. Docling standardisiert und konvertiert Dokumente in KI-fähige Formate mit Rückverfolgbarkeit auf Quellcodeebene, während die NVIDIA Nemotron-Modelle die Erfassung multimodaler Inhalte beschleunigen. Erste Ergebnisse zeigen einen deutlich höheren Durchsatz im Vergleich zu anderen Open-Source-Modellen, bei gleichbleibender oder verbesserter Genauigkeit, sofern eine GPU-beschleunigte Infrastruktur verfügbar ist.
GPU-optimierte Infrastruktur für On-Premise- und regulierte Bereitstellungen
IBM und NVIDIA erweitern ihre Dateninitiativen auf die Infrastrukturebene. NVIDIA hat sich laut Anbieter für das IBM Storage Scale System 6000 entschieden, um 10 PB an Hochleistungsspeicher bereitzustellen, der grosse Datenmengen für seine GPU-nativen Analyse-Engines bedient, wobei die einheitliche Datenzugriffs-Ebene und der massive parallele Durchsatz von IBM mit den GPU-Pipelines von NVIDIA kombiniert werden sollen. IBM Storage Scale 6000 ist für NVIDIA DGX-Plattformen zertifiziert und validiert.
Für Unternehmen und Behörden, die Datenresidenz und regulatorische Kontrolle benötigen, prüfen IBM und NVIDIA demnach die Integration von IBM Sovereign Core und NVIDIA-Infrastruktur sowie NVIDIA Nemotron-Modellen, die darauf abzielen, GPU-intensive KI-Workloads zu ermöglichen, die vollständig innerhalb regionaler Grenzen ausgeführt werden – d.h. keine Abstriche bei Governance oder Compliance.
Weiterentwicklung des Enterprise-KI-Stacks mit IBM, NVIDIA und Red Hat
IBM und NVIDIA vertiefen ihre Partnerschaft in den Bereichen Cloud- und Unternehmensberatung, um die Einführung von Unternehmens-KI bei Kunden voranzutreiben. IBM plant, NVIDIA Blackwell Ultra-GPUs Anfang des zweiten Quartals 2026 auf der IBM Cloud für groß angelegtes Training, Inferenz mit hohem Durchsatz und KI-Schlussfolgerungen anzubieten. Diese Technologie soll dann auch in die Red Hat AI Factory mit NVIDIA sowie in VPC-Server mit Compliance- und Datenresidenz-Kontrollen auf Unternehmensniveau integriert werden.

Abb.: IBM Storage Scale 6000 (Bildquelle: IBM).
Quelle / externer link > https://www.ibm.com/products/storage-scale-system
6. KIOXIA
KIOXIA Super-High-IOPS-SSD als Speichererweiterung der Storage-Next-Architektur von NVIDIA (SSD-Modell für GPU-initiierte KI-Workloads):
KIOXIA Europe GmbH hat die Entwicklung einer KIOXIA Super-High-IOPS-SSD angekündigt. Der neue SSD-Typ ermöglicht es GPUs laut Hersteller, direkt auf den Hochgeschwindigkeits-Flashspeicher zuzugreifen und diesen als Erweiterung des High Bandwidth Memory (HBM) in KI-Systemen zu nutzen. Die neue Super-High-IOPS-SSD, die als GP-Serie vertrieben wird, wurde denach speziell entwickelt, um den steigenden Leistungsanforderungen von KI und High-Performance-Computing gerecht zu werden. Sie stellt eine größere, für GPUs zugängliche Speicherkapazität bereit und ermöglicht ihnen dadurch schnelleren Datenzugriff für KI-Workloads.
NVIDIA Storage-Next: Die Initiative für moderne KI-Workloads
Die Storage-Next-Initiative von NVIDIA adressiert den erwarteten Wandel von rechenintensiven hin zu datenintensiven Workloads sowie den wachsenden Bedarf an GPU-zugänglichem Speicher, der derzeit durch die Größe des HBM begrenzt ist. Durch die Erweiterung des nutzbaren GPU-Speicherraums können größere Datensätze verarbeitet und die GPU-Auslastung verbessert werden, da auf diese Weise mehr Daten näher an die tatsächliche Rechenressourcen verlagert werden. Im Rahmen der Storage-Next-Initiative ruft NVIDIA SSD-Hersteller auf, Laufwerke zu entwickeln, die für GPU-initiierte KI-Workloads optimiert sind. Effektiv ist gefordert, GPUs den Zugriff auf Flash-basierten Speicher zu ermöglichen, um die HBM-Kapazität effektiv zu erhöhen.
KIOXIA unterstützt nach vorliegenden Angaben diese Initiative mit den SSDs der GP-Serie, die auf latenzarmem, hochleistungsfähigem KIOXIA XL-FLASH Storage Class Memory basieren. Im Vergleich zu herkömmlichen TLC-SSDs von KIOXIA bietet diese Lösung eine "einzigartige Positionierung für diese Architektur" und ermöglicht höhere IOPS, feinere Granularität beim Datenzugriff (512 Byte) sowie einen geringeren Energieverbrauch pro I/O-Vorgang.
Steigender Bedarf an KV-Cache: Darüber hinaus wachsen KI-Modelle rasant in Richtung Billionen von Parametern, während sich Kontextfenster auf Millionen von Tokens erweitern. Dies führt zu einem Anstieg des Bedarfs an KV (Key Value)-Cache. Architekturen wie NVIDIA Context Memory Storage (CMX) tragen diesem Bedarf Rechnung, indem sie die Speicherhierarchie über den GPU-Speicher hinaus mithilfe leistungsfähiger Speicherlösungen erweitern.
Die PCIe-5.0-E3.S-SSDs der CM9-Serie von KIOXIA mit einer TLC-Kapazität von 25,6 TB bei 3 DWPD bieten laut Hersteller die erforderliche Leistung, Kapazität und Haltbarkeit zur Unterstützung solcher großskaligen Inferenzumgebungen. KIOXIA ist nach eigenen Angaben überzeugt, dass (Zitat) „diese Speicherklasse eine entscheidende Rolle beim Aufbau effizienter und kostenoptimierter KI-Infrastruktur spielen wird.“

Abb.: KIOXIA GP Flash SSD (Bildquelle: KIOXIA).
Axel Störmann, Chief Technology Officer und Vice President bei KIOXIA Europe: „Indem GPUs direkten Zugriff auf Hochgeschwindigkeits-Flashspeicher als Erweiterung des HBM erhalten, ermöglicht diese neue Klasse von Super-High-IOPS-SSDs schnellere und effizientere KI-Workloads. Das ist insofern notwendig, da sich das Computing zunehmend in Richtung datenintensiver Anwendungen entwickelt…“. Muster der GP-Serie von KIOXIA sollen laut Anbieter an ausgewählte Kunden ab dem dritten Quartal 2026 ausgeliefert werden.
7. NetApp
NetApp AI Data Engine (AIDE) Ankündigung
AIDE ist ein einheitlicher KI-Daten-Plattform-Stack, der gemeinsam mit NVIDIA entwickelt und in das NVIDIA AI Data Platform Referenzdesign integriert wurde.
Wenn Daten der Treibstoff für KI sind, ist es für wirklich transformative KI entscheidend, die besten Daten aufzufinden und zu nutzen. NetApp AIDE soll diesen Bedarf durch einen automatisch erstellten und kontinuierlich aktualisierten globalen Metadatenkatalog mit leistungsstarken Suchfunktionen decken helfen.
Entscheidend ist danach, dass der NetApp AIDE Metadatenkatalog laut Entwickler über standardmäßige Dateisystem-Metadaten hinausgeht und Dateiinhalte aktiv analysiert, um Metadaten semantisch direkt am Speicherort anzureichern. So müssen Daten nicht mehrfach verschoben werden, was zusätzliche Sicherheitsrisiken und Kosten verursachen würde.
Mithilfe dieser angereicherten Metadaten können Unternehmen Daten finden, kuratieren, nutzen und kontrollieren, um in der gesamten KI-Datenpipeline stets die korrekten und aktuellen Daten bereitzustellen. Dies gilt von der Auswahl und Transformation über den Abruf und die Bereitstellung bis hin zu KI-Applikationen und KI-Agenten.
Um die Fähigkeiten der NetApp Datenplattform weiter zu stärken, plant NetApp NVIDIA STX eine modulare, rack-skalierte Storage-Referenzarchitektur für agentische KI, zu unterstützen. STX, entwickelt auf Basis von NVIDIA Vera Rubin und NVIDIA BlueField-4 DPUs (Data Processing Units), stellt eine Daten-Engine mit spezialisierter Speicherebene für KV-Cache-Speicher dar, die Energieeffizienz, Durchsatz und Sicherheit verbessert.
Werden die Datenmanagement-Fähigkeiten von NetApp in diese neue Referenzarchitektur integriert, sollen Kunden die Lücke zwischen massiver KI-Rechenleistung und unstrukturiertem Datenspeicher schließen können, indem sie die intelligente Datenverwaltung zentralisieren.
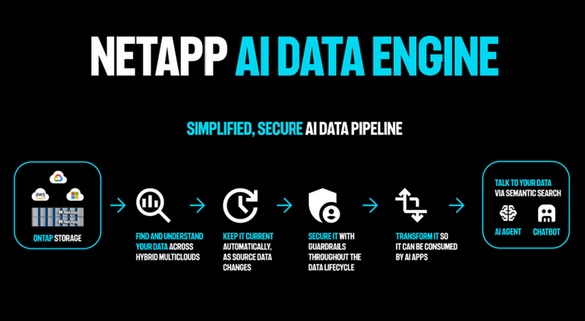
Abb.: NetApp AI Data Engine (AIDE). Bildquelle: NetApp.
Externer Link > https://www.netapp.com/blog/ai-data-engine-transform-enterprise-ai-smart-data/
8. Everpure (Anmerkung: ex "Pure Storage")
Evergreen//One for AI und Data Stream Beta
Beschleunigter Übergang vom Pilotprojekt zur Produktion mit Benchmark-geprüfter Leistung, automatisierten Datenpipelines und flexiblem Nutzungsmodell
Everpure stellt Evergreen//One for FlashBlade//EXA und die bevorstehende Beta-Version von Everpure Data Stream vor.
Ziel ist es danach, Unternehmen dabei zu helfen, Kosten- und Komplexitätsbarrieren abzubauen, die KI-Projekte verzögern. Evergreen//One (EG1) for AI wird nun um FlashBlade//EXA erweitert und bietet die enorme Leistung, Skalierbarkeit und den Durchsatz, die für anspruchsvolles Training und Inferenz erforderlich sind. Ergänzend dazu beschleunigt die Beta-Version von Everpure Data Stream, die später im Jahr 2026 auf den Markt kommt, die Zeit bis zum Ergebnis. Everpure Data Stream beseitigt die Reibungsverluste der manuellen Datenbewegung durch eine direkte, automatisierte Pipeline von der Datenerfassung bis zur Inferenz.
KI-Implementierungen sind dann erfolgreich, wenn die Infrastruktur dafür sorgt, dass GPUs mit maximaler Kapazität laufen. Everpure richtet FlashBlade//EXA auf die modulare NVIDIA STX-Referenzarchitektur aus, um die nächste Generation von KI-Fabriken zu unterstützen, die auf der Vera Rubin-Plattform basieren. Durch die Kombination der Leistung und Skalierbarkeit von EXA mit STX-Komponenten wie BlueField-fähigen Speichercontrollern und Kontextspeicherarchitekturen optimiert Everpure die KI-Pipeline – von der Datenaufbereitung bis zur Inferenz mit langen Kontextfenstern. Diese Architektur ist speziell auf die Anforderungen an hochleistungsfähigen Kontextspeicher für Inferenz im Gigaskalenbereich ausgelegt und bietet den für agentenbasierte Workflows und mehrstufige Schlussfolgerungssysteme in großem Maßstab erforderlichen Datenzugriff mit geringer Latenz.Darüber hinaus bildet die Erweiterung der NVIDIA-Certified Storage (NVCS)-Validierung mit FlashBlade//EXA die Grundlage für Vertrauen in den gesamten Stack. Diese Integration schafft einen klaren Weg zur NVCS ‘NCP’-Zertifizierungsstufe, die gezielt auf die Referenzarchitekturen von NVIDIA Cloud Partner (NCP) abgestimmt ist.
Durch die Kombination der Hardware von Supermicro mit dem softwaredefinierten Speicher von Everpure können Unternehmen den wahren Wert ihrer Daten schnell erschließen. Da Enterprise-KI-Fabriken eine KI-Datenplattform benötigen, um KI-fähige Daten aufzubereiten und bereitzustellen, unterstützt Everpure auch beschleunigte Plattformen wie die NVIDIA RTX PRO 6000 Blackwell Server Edition und wird die Unterstützung auf die NVIDIA RTX PRO 4500 Blackwell Server Edition GPU ausweiten.
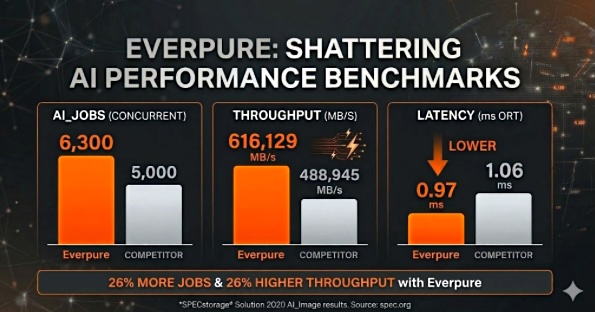
Abb.: Bildquelle / Everpure. Externer Link > https://www.purestorage.com/
9. DELL Technologies (Storage)
Dell AI Data Platform with NVIDIA beschleunigt Enterprise-KI mit Datenorchestrierung und Storage-Software. Automatisierung des gesamten KI-Datenlebenszyklus für anspruchsvolle agentenbasierte KI-Workloads.
Dell Technologies stellt Weiterentwicklungen seiner Dell AI Data Platform with NVIDIA vor, die Unternehmen dabei helfen sollen, Daten aufzuspüren und für KI nutzbar zu machen. Dell Technologies und NVIDIA adressieren nach eigenen Angaben "eines der größten Hindernisse für den erfolgreichen Einsatz von Enterprise-KI: Daten, die zu langsam bereitgestellt werden, zu oft in Silos feststecken oder zu chaotisch organisiert sind, um sie zu nutzen. Als Kernkomponente der Dell AI Factory with NVIDIA macht die Dell AI Data Platform with NVIDIA Unternehmensdaten für KI-Anwendungen zugänglich."
Unternehmen, die die Plattform einsetzen, sollen im Vergleich zu klassischen Computing-Ansätzen von einer bis zu zwölfmal schnelleren Vektorindexierung, einer bis zu dreimal schnellerer Datenverarbeitung und einer bis zu 19fach verkürzten Time To First Token (TTFT) profitieren können (Quelle: DELL)
Leistungsfähige Storage-Software für optimale GPU-Nutzung
Bei der Überführung von KI-Experimenten in den produktiven Betrieb ist der Storage oft die kritische Komponente. Klassische Storage-Architekturen werden langsamer, wenn sie wachsen, und verursachen Engpässe, sodass GPUs nicht ausgelastet werden und Infrastrukturinvestitionen ungenutzt bleiben. Die für KI optimierten Storage-Engines von Dell Technologies lösen das Problem mit maßgeschneiderten Architekturen, die auch in großen Umgebungen Höchstleistung liefern. Zu den wichtigsten Neuerungen auf Architekturseite zählen:
"Die optimierte Fabric-Architektur mit direkten Storage-Zugriffen verhindert Leistungseinbrüche und hält GPUs ausgelastet. Lightning FS integriert sich in NVIDIA-basierte KI-Infrastrukturen und stellt sicher, dass Trainings- und Inferencing-Workloads mit voller Geschwindigkeit laufen.
Dell Exascale Storage erlaubt IT-Teams die flexible Bereitstellung von Dell-Software für Object und Parallel File Storage auf den neuesten PowerEdge-Servern.
Dell Lightning File System, das Hochleistungswerte für KI-Training und Inferencing bietet - laut Anbieter bis 150 GB/s pro Rack-Einheit.
Unternehmen können Storage-Ressourcen von Dell PowerScale, Dell ObjectScale und/oder Dell Lightning File System auf einer gemeinsamen Hardware-Plattform zur Verfügung stellen, um KI-Anwendungen und HPC-Umgebungen mit Daten zu versorgen, etwa Hochfrequenzhandel und Neoclouds. Mit Support für NVIDIA CX-8 und CX-9 SuperNICs und der geplanten Netzwerk-Konnektivität von bis zu 800 GbE kann mit Exascale eine Lese-Performance von bis zu 6 TB/s pro Rack erreicht werden.
Die Unterstützung der NVIDIA CMX Context Memory Storage Platform und die Inference-Beschleunigung mit KV Cache auf geteiltem Storage über Systeme mit Dell PowerScale, Dell ObjectScale und Dell Lightning File System hinweg erlaubt es laut Anbieter, KV Cache aus dem GPU-Speicher auf Dell CMX Storage und geteilten Netzwerk-Storage auszulagern – je nach Leistungsanforderungen."
Leistung von Dell PowerScale
Neue Tests des Anbieters zeigen, dass die softwaregesteuerte pNFS-Architektur (Parallel Network File System) von Dell PowerScale in KI-Umgebungen eine bis zu sechsmal bessere Performance bei großen Dateien liefern kann als NFSv311. Dadurch werden GPU-intensive KI-Workloads kontinuierlich mit Daten versorgt, Engpässe in der gesamten Pipeline reduziert und GPUs optimal ausgelastet, sodass sie nicht untätig auf Daten warten. Zu den Neuerungen beim Thema Datenorchestrierung zählen:
"Die Dell Data Orchestration Engine, in der Technologie des kürzlich von Dell Technologies übernommenen Spezialisten Dataloop steckt, verbessert die Art und Weise, wie Unternehmen ihre Daten für die KI-Nutzung operationalisieren. Die No-Code-/Low-Code-Engine orchestriert den KI-Datenlebenszyklus – von der automatischen Data Discovery über die Klassifizierung und Anreicherung der Daten bis hin zur Transformation großer strukturierter, unstrukturierter und multimodaler Datenmengen in Datensätze, die die KI optimal verarbeiten kann.
Durch die Automatisierung der Pipelines mit aktivem Lernen und „Human in the Loop“-Workflows sollen Unternehmen laut Dell die Qualität ihrer Datensätze und damit auch die Modellgenauigkeit kontinuierlich verbessern können; dies bei voller Kontrolle und unter Wahrung der Governance.
Der Dell Data Orchestration Market Place liefert mit einer kuratierten Bibliothek voller NVIDIA Inference Microservices (NIMs), NVIDIA AI Blueprints und mehr als 200 anderen Modellen, Anwendungen und Templates sofort einsatzbereite Daten-Workflows, die Unternehmen direkt bereitstellen können, sodass die aufwendige Eigenentwicklung wegfällt."
Dell Technologies unterstützt den neuesten NVIDIA AI-Q Blueprint. Dieser ermöglicht es Unternehmen, anpassbare KI-Agenten zu erstellen, die für bessere Entscheidungen nutzbare Erkenntnisse liefern. Die in die Dell AI Data Platform integrierten, NVIDIA-beschleunigten Daten-Engines sorgen für leistungsfähige Pipelines für Datenaufbereitung, Information Retrieval und Reasoning – sowohl mit strukturierten als auch unstrukturierten Daten.
Unterstützt wird darüber hinaus NVIDIA STX, ein neues, modulares Referenzdesign mit NVIDIA Vera Rubin NVL72, NVIDIA BlueField-4 DPUs und NVIDIA Spectrum-X Ethernet Networking, das Datenmanagement, Datenverarbeitung und Information Retrieval beschleunigt. Ein neuer KI-Assistent in der Dell Data Analytics Engine erweitert SQL-Analysen um ein dialogorientiertes Sprachinterface.
KI-Agenten bereitstellen, die Zugriff auf strukturierte Daten benötigen: Die Einführung der NVIDIA RTX PRO Blackwell Server Edition GPUs in die Dell AI Data Platform with NVIDIA bringt Hardware-Beschleunigung direkt in den Datenplattform-Layer. Beschleunigte CUDA-X-Bibliotheken wie NVIDIA cuDF für die Verarbeitung strukturierter Daten und NVIDIA cuVS für Vektorindexierung und Suche in unstrukturierten Daten arbeiten mit den Daten-Engines von Dell Technologies und optimierten Infrastrukturen zusammen.
Unterstützung für NVIDIA NVQLink und CUDA-Q: Unternehmen und Forschungseinrichtungen erhalten dadurch die Möglichkeit, neuartige Anwendungsfälle zu erkunden, die Quantencomputing und klassisches Computing kombinieren. Damit wird die Basis geschaffen für Durchbrüche bei der Entwicklung neuer Medikamente und fortschrittliche Simulationen in der Materialwissenschaft. Die Kombination aus Quantum Processing Units (QPUs) und NVIDIA-beschleunigtem Computing bietet laut Anbieter" Kontrolle und Fehlerkorrektur auf vertrauenswürdigen PowerEdge-Servern von Dell Technologies".
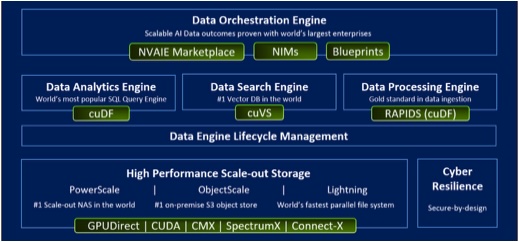
Abb.: Daten-Engines von Dell Technologies werden von NVIDIAs KI-Lösungen beschleunigt und automatisieren den gesamten Datenlebenszyklus. (Quelle: Dell Technologies). Externer Link > https://www.dell.com/en-us/blog/scale-your-ai-ambitions-with-dell-storage-and-nvidia/
10. Cloudian
Cloudian HyperStore NVIDIA-Certified Storage
Die Zertifizierung bietet NVIDIA-Kunden einen verifizierten Weg, um Exabyte-skalierbaren Objektspeicher mit nativer S3-API-Kompatibilität für AI-Factory-Umgebungen bereitzustellen.
"HyperStore ab Version 8.2.6 hat die Zertifizierung als NVIDIA-Certified Storage auf Foundation-Level erhalten. NVIDIA-Kunden erhalten so die Möglichkeit, NVIDIA-zertifizierten, Exabyte-skalierbaren Objektspeicher mit nativer S3-API-Kompatibilität für KI-Training, Finetuning, Inferenz und Datenpipeline-Workloads einzusetzen.
NVIDIA-Certified Storage ist ein Validierungsframework, das Storage-Lösungen von Partnern anhand realer KI-Workloads und synthetischer Benchmarks im großen Maßstab testet. Cloudian hat nun die Zertifizierung auf Foundation-Level erreicht. Bewertet werden dabei die kritischen I/O-Muster moderner AI Factories – darunter sequenzielle Lesezugriffe für das Training, Random I/O für Inferenz sowie latenzarmer Zugriff für Key-Value-Cache- und RAG (Retrieval Augmented Generation)-Pipelines – ebenso wie zentrale Enterprise-Anforderungen wie Quality of Service, Multi-Tenancy und Sicherheit.
S3-nativer Objektspeicher für die AI FactoryCloudian HyperStore bringt ein differenziertes Leistungsprofil in NVIDIA-KI-Infrastrukturumgebungen ein. Als speziell entwickelte Objektspeicherplattform bietet HyperStore eine besonders umfassende S3-API-Kompatibilität und ermöglicht so die nahtlose Integration mit Cloud-nativen Anwendungen und KI-Frameworks, die auf die S3-Schnittstelle als Standard für den Datenzugriff setzen. Die verteilte Architektur skaliert unterbrechungsfrei von Terabytes bis Exabytes, während das Software-definierte Design auf Standardhardware oder Cloudian-Appliances betrieben werden kann und Unternehmen volle Kontrolle über ihre Infrastruktur gibt."
Abb.: HyperScale AI Data Platform (Bildquelle: Cloudian).
Externer Link > https://cloudian.com/
11. STARBURST
Starburst zeigt Plattform für KI-Inferenz und leistungsstarke Data Analytics mit NVIDIA Vera CPU
Als offene hybride Lakehouse-Plattform ist Starburst für NVIDIAs neue Inferenz-Compute-Plattform optimiert. Unternehmen können damit Echtzeit-KI und Datenanalyse verteilten Daten ausführen.
Starburst hat seine neue, auf Inferenz ausgerichtete Compute-Plattform, auf der NVIDIA GTC in San Jose vorgestellt. Starburst-Kunden erhalten danach unmittelbaren Zugriff auf deutlich höhere Abfrageleistung, KI-Inferenz mit geringerer Latenz sowie erhebliche Kosteneffizienz.
Die Trino-basierte Plattform von Starburst ist positioniert, um von Vera, NVIDIAs Rechenzentrums-CPU der nächsten Generation für schnelle Datenanalyse, zu profitieren. Während konkurrierende Plattformen die Zentralisierung von Daten in proprietären Data Warehouses voraussetzen, bevor KI darauf aufsetzen kann, bietet Starburst nach eigenen Angaben den „hybriden, föderierten und kontrollierten Datenzugriff in Inferenzgeschwindigkeit direkt dort, wo die Daten gespeichert sind – über Data Lakes, Data Warehouses und operative Systeme hinweg, ohne Datenverschiebung oder -duplizierung.“
Da sich die Anforderungen von Unternehmen von der Modellentwicklung hin zur produktiven Inferenz verlagern, die agentenbasierte KI, Retrieval-Augmented Generation (RAG) und Echtzeitanwendungen ermöglicht, adressiert NVIDIA Vera die Leistungs- und Kostenbeschränkungen, welche die flächendeckende Einführung von KI bisher eingeschränkt haben.
Abb.: Bildquelle, NVIDIA.
Kommentar Justin Borgman, Gründer und CEO von Starburst: „Die Zukunft von KI in Unternehmen hängt vom schnellen Zugriff auf kontrollierte Daten ab. Mit NVIDIA Vera will Starburst Echtzeitanalysen und -inferenzen direkt dort ermöglichen, wo die Daten gespeichert sind.“
Externer Link > https://www.starburst.io/
12. KI Sicherheit mit Trend Micro
TrendAI - ein Geschäftsbereich von Trend Micro - tritt dem HPE Unleash AI-Partnerprogramm bei, um Organisationen dabei zu unterstützen, ihre KI-Initiativen auf Basis von HPE Private Cloud AI schneller und sicherer umzusetzen.
Durch die Integration von TrendAI Vision One in die Plattform ergeben sich für Unternehmen umfassende Sicherheitsfunktionen über den gesamten KI-Stack hinweg – von Infrastruktur über Modelle bis zu Anwendungen.
Neue Integration mit NVIDIA DSX Air ermöglicht es, die Sicherheit von KI-Fabriken bereits vor der Bereitstellung zu entwerfen, zu testen und zu validieren. Mithilfe digitaler Zwillinge ihrer Rechenzentrumsinfrastruktur können Sicherheitskontrollen frühzeitig simuliert und Risiken im KI-Lebenszyklus reduziert werden.
TrendAI unterstützt die neue Open-Source-Laufzeitumgebung NVIDIA OpenShell, um Sicherheits- und Governance-Funktionen für agentische KI bereitzustellen. Damit können Unternehmen autonome KI-Agenten mit klar definierten Vertrauensgrenzen, kontinuierlicher Risiko-Transparenz und Laufzeitkontrollen betreiben."
Querverweis:
Unser Blogpost > Wie Künstliche Intelligenz die Anforderungen an IT-Infrastruktur und Datenspeicher erhöht
Unser Beitrag > Nvidia GTC 2025: Storage- und Data-Management Update