
Einheitliche Plattform für kollaborative KI als Grundlage für den breiten Einsatz von Agentic AI im eigenen Unternehmen. Weiterentwicklung der Red Hat Enterprise-AI-Plattform…
Ankündigungsübersicht
Red Hat AI 3 hat am 14. Okt. eine umfangreiche Weiterentwicklung seiner Enterprise-AI-Plattform angekündigt. Die Kombination der neuesten Funktionen von Red Hat AI Inference Server, Red Hat Enterprise Linux AI (RHEL AI) und Red Hat OpenShift AI soll dabei helfen, die Komplexität von hochperformanter KI-Inferenz deutlich zu reduzieren. Unternehmen können ihre Workloads dann sehr viel schneller von einem Proof-of-Concept in die Produktionsphase überführen und die Zusammenarbeit rund um KI-gestützte Anwendungen verbessern.
Hintergrund
Viele Unternehmen haben inzwischenn die experimentelle Phase ihrer KI-Projekte abgeschlossen und stehen nun vor erheblichen Herausforderungen – darunter Datenschutz, Kostenkontrolle und das Management einer Vielzahl von unterschiedlichen Modellen. Red Hat AI 3 zielt mit der Ankündiguhg darauf ab, Lösungen für diese Herausforderungen zu liefern.
Die Plattform stellt laut dem Anbieter eine einheitliche konsistente Umgebung bereits, mit der Investitionen in leistungsstarke Computing-Technologien maximiert werden können. Damit soll es auch möglich sein, KI-Workloads schneller zu skalieren sowie über hybride Multi-Vendor-Umgebungen zu verteilen – und gleichzeitig die teamübergreifende Zusammenarbeit an modernen KI-Workloads wie Agenten zu verbessern. Aufbauend auf offenen Standards bietet Red Hat AI 3 laut Entwickler (Zitat) „Unterstützung für jedes Modell auf jedem KI-Beschleuniger, von Rechenzentren über Public-Cloud- und souveräne KI-Umgebungen bis hin zum Edge.“
Vom Training in die Praxis
Wenn Unternehmen KI-Projekte in die Produktion überführen, verschiebt sich der Fokus von Training und Feinabstimmung der Modelle hin zur Inferenz – also der Produktionsphase. Red Hat AI 3 legt den Schwerpunkt auf Inferenz, die auf den erfolgreichen Community-Projekten vLLM und llm-d sowie der Expertise zur Modelloptimierung von Red Hat basiert, um die produktionsreife und zuverlässige Bereitstellung großer Sprachmodelle (LLMs) zu ermöglichen.
Um Verantwortliche dabei zu unterstützen, das Maximum aus ihren hochwertigen Hardwarebeschleunigern herauszuholen, führt Red Hat OpenShift AI 3 die allgemeine Verfügbarkeit von llm-d ein, eine native Ausführung von LLMs auf Kubernetes. llm-d ermöglicht verteilte Inferenz, nutzt den Ansatz der Kubernetes-Orchestrierung und die Performance von vLLM in Kombination mit zentralen Open-Source-Technologien wie Kubernetes Gateway API Inference Extension, NVIDIA Dynamo Low Latency Data Transfer Library (NIXL) sowie DeepEP Mixture of Experts (MoE) Communication Library.
Vorteile von llm-d für Unternehmen (Quelle, Anbieter):
Sinkende Kosten und steigende Effizienz durch disaggregiertes Serving, was zu einer besseren Performance pro investiertem Euro führen kann.
Bedienung über vordefinierte „Well-lit Paths“, die die Bereitstellung von Modellen auch im großen Maßstab auf Kubernetes optimieren.
Flexibilität durch plattformübergreifende Unterstützung der Bereitstellung von LLM-Inferenz auf verschiedenen Hardware-Beschleunigern, darunter NVIDIA und AMD.
llm-d baut auf vLLM auf und entwickelt die Single-Node-Hochleistungs-Inferenz-Engine zu einem verteilten, konsistenten und skalierbaren Serving-System weiter. Ziel ist eine vorhersehbare Performance, messbarer ROI und effektive Infrastrukturplanung.
Alle Verbesserungen adressieren danach direkt die Herausforderungen, die mit der Verarbeitung hochvariabler LLM-Workloads und der Bereitstellung umfangreicher Modelle wie Mixture-of-Experts-Modellen (MoE) verbunden sind.
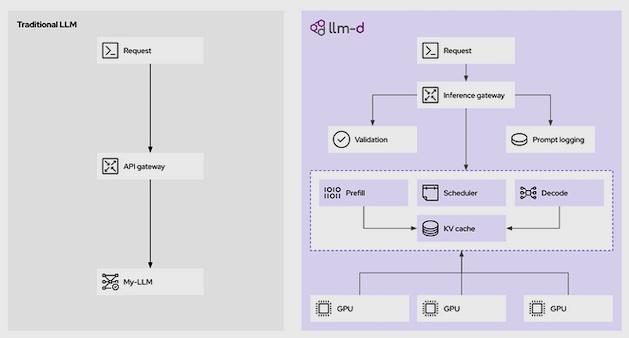
Bildquelle: Red Hat
Anmerkung: Aus Gründen von Latenz, Compliance oder des Datenschutzes nimmt das Selbsthosting mit Open-Source-Modellen auf eigener Hardware gerade zu; Unternehmen behalten so die volle Kontrolle über Ihre KI-Entwicklung. Das Open-Source-Framework llm-d wird aktuell von Red Hat, IBM und Google unterstützt.
llm-d soll die Herausforderungen bewältigen, die Skalierung von LLMs vom Experimentierstadium in einen produktionsreifen Dienst zu überführen, was bislang (ohne llm-d) mit teils erheblichen Kosten und Komplexität verbunden ist. llm-d konzentriert sich auf den Kern des Problems: die KI-Inferenz – den Prozess, bei dem ein Modell Ergebnisse für Eingabeaufforderungen, Agenten, Retrieval-Augmented Generation (RAG) und mehr generiert.
Einheitliche Plattform für kollaborative KI
Red Hat AI 3 wurde entwickelt, um die Arbeit mit KI stark zu vereinfachen und durch die Förderung von teamübergreifender Zusammenarbeit und einheitlichen Workflows Mehrwerte zu schaffen. Die Plattform bietet sowohl Plattform- als auch KI-Ingenieuren eine gemeinsame Umgebung, um ihre KI-Strategie gemeinsam umzusetzen. Zu den neuen Funktionen, die darauf ausgerichtet sind, die für die Skalierung vom Proof-of-Concept bis zur Produktion erforderliche Produktivität und Effizienz zu gewährleisten, gehören:
Model-as-a-Service-Funktionen (MaaS): sie basieren auf verteilter Inferenz und ermöglichen es IT-Teams, als eigene MaaS-Anbieter zu agieren, gängige Modelle zentral bereitzustellen und sowohl KI-Entwicklern als auch KI-Anwendungen On-Demand-Zugriff zu gewähren. Dies soll ein besseres Kostenmanagement bieten und unterstützt Anwendungsfälle, die aufgrund von Datenschutz- oder Privacy-Bedenken nicht auf öffentlichen KI-Diensten ausgeführt werden können.
Das Fundament für die nächste Generation von KI-Agenten
KI-Agenten sind dabei, die Art und Weise, wie Anwendungen entwickelt werden, grundlegend zu verändern. Um die Erstellung und Bereitstellung von Agenten zu beschleunigen, hat Red Hat einen Unified API Layer auf Basis des Llama Stack eingeführt, um die Entwicklung konkret an Branchenstandards wie OpenAI auszurichten. Darüber hinaus gehört Red Hat zu den frühen Anwendern des Model Context Protocol. Der aufstrebende leistungsstarke Standard soll die Interaktion von KI-Modellen mit externen Tools vereinfachen, eine zentrale Funktion moderner KI-Agenten.
Red Hat AI 3 führt darüber hinaus ein neues modulares und erweiterbares Toolkit zur Modellanpassung ein, das auf der bestehenden InstructLab-Funktionalität aufbaut. Es umfasst spezialisierte Python-Bibliotheken, die Entwicklern mehr Flexibilität und Kontrolle bieten soll. Grundlage des Toolkit sind Open-Source-Projekte wie Docling für die Datenverarbeitung, das die Aufnahme unstrukturierter Dokumente in ein KI-lesbares Format vereinfacht.
Außerdem enthält das Toolkit ein flexibles Framework zur Erzeugung synthetischer Daten sowie einen Trainings-Hub für das Finetuning von LLMs. Ein integrierter Evaluations-Hub unterstützt KI-Ingenieure bei der Überwachung und Validierung ihrer Ergebnisse – und ermöglicht es ihnen, ihre eigenen Daten gezielt zu nutzen, um noch genauere und relevantere KI-Modelle zu entwickeln.
Querverweis:
Unser Beitrag > Update zum Red Hat Summit und AnsibleFest 2025 in Boston (MA)
Unser Beitrag > Schnelle Entwicklung von KI-Agenten: Amazon Web Services macht Bedrock AgentCore allgemein verfügbar
Unser Beitrag > Neue Docker-Funktionen zur Entwicklung KI-gestützter Agentenanwendungen